
60
Data Engineering Pipeline with AWS Step Functions, CodeBuild and Dagster
An end-to-end project to collect, process, and visualize housing data.
The goal of this project is to collect Slovak real estate market data, process it, and aggregate it. Aggregated data is consumed by a web application to display a price map of 2 Slovak cities - Bratislava and Kosice.
Data is collected once per month. My intention is to create a snapshot of the housing market in a given month and check on changing price trends, market statistics, ROIs, and others. You could call it a business intelligence application.
Collect -> Process -> Visualize // 🏠📄 -> 🛠 -> 💻📈Currently, the web application frontend shows the median rent and sell prices by borough. Still a WIP 💻🛠.

I have a backlog of features I want to implement in the upcoming months. Also, feature ideas are welcome 💡.
Why am I building this?
I am interested in price trends and whatnot. Plus, I wanted to build a project on AWS using new exciting technologies like Dagster.
I am interested in price trends and whatnot. Plus, I wanted to build a project on AWS using new exciting technologies like Dagster.
It's not a tutorial by any means. More of a walkthrough and reasoning behind the design and gotchas along the way. I will talk about:
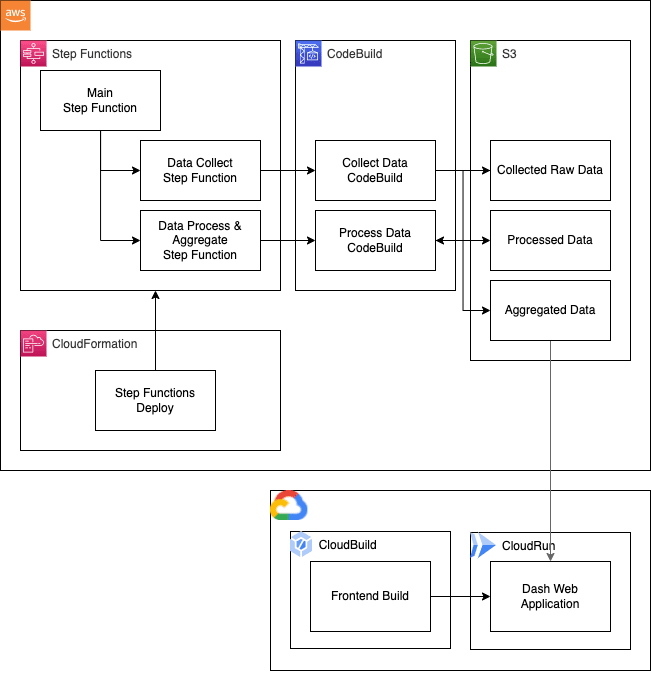
From technical perspective the project is implemented via 3 separate microservices. This allows flexibility in deployments, managing Step Functions, and developing the project part-by-part.

It is a side project so I have to keep costs as low as possible while having a "fully running product". I built the project around serverless services which introduced a couple of constraints to keep the prices low. Mainly using GCP along AWS.
Why AWS and GCP?
Cost savings 💸.
I wanted to build this project solely on AWS... but AWS AppRunner(GCP CloudRun analog), to run the web application does not support scale down to 0 instances. Meaning, there's fixed base cost for 1 running instance which I wanted to avoid.
GCP CloudRun supports scale down to 0 instances which is ideal. I will only pay for the resources when a web application is accessed and I do not have to keep a constantly running instance.
I will write about the less known AWS Services and the reason I selected them for the project. Everyone knows about S3. Plus, Dagster is an awesome pipeline orchestrator.
AWS Step Functions is a low-code, visual workflow service that to build distributed applications, automate IT and business processes, and build data and machine learning pipelines using AWS services.
There is a great blog post about AWS Step Function use cases. It goes in-depth on patterns, use-cases, and pros/cons of each. Check this link.
For my use-cases it was the ideal orchestration tool. Because:
AWS CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy. With CodeBuild, you don’t need to provision, manage, and scale your own build servers.
I use CodeBuild as it's the easiest way to get long running on-demand compute. Has native support in Step Functions, and comes with 100 free build minutes. It would be possible to use EC2 instances to execute workloads in the same manner but CodeBuild is quicker to spin up and requires less maintenance. Not to mention it's easy to scale, and run in parallel.
The drawback is that build jobs are ephemeral and therefore data is lost if not saved. This required a bit of engineering to handle errors gracefully in the containers and uploading data artifacts right after they are produced.
"Dagster is a data orchestrator for machine learning, analytics, and ETL. It lets you define pipelines in terms of the data flow between reusable, logical components, then test locally and run anywhere." Great intro here.
I tried two other tool before settling on Dagster. Namely, Prefect, and Kedro. While both great, they were not ideal for this project. Prefect needs a running Docker and I felt Kedro had to steep learning curve. Also Kedro is intended for ML project management. When it comes to Kedro, I will dig deeper into it in future projects as I liked how it's organized and also used their Data Engineering convention in this project. I will talk about it later.
Back to Daster, I ultimately choose it because it doesn't need a running docker instance - it's a
pip install dagster away, lightweight, extensible, and can be run anywhere - locally, Airflow, Kubernetes, you choose.Dagster comes in two parts. Dagster - orchestration and Dagit - Web UI. They are installed separately which proven to be a benefit in my development workflow.
As already mentioned I use CodeBuild as an accessible compute resource where I run my Dagster pipeline. I don't think Dagster was intended to be used this way (inside a Docker build) but everything worked seamlessly.
Main Step Function
Everything is orchestrated by the Main state machine. Which triggers the Data Collect and Data Process state machines containing the CodeBuild blocks where "real work" is done.
Everything is orchestrated by the Main state machine. Which triggers the Data Collect and Data Process state machines containing the CodeBuild blocks where "real work" is done.
My main state machine contains two choice blocks. This allows to run collect and process independently by defining an input at execution trigger.
# Main Step Function inputs
{
"run_data_collect": true or false,
"run_data_process": true or false
}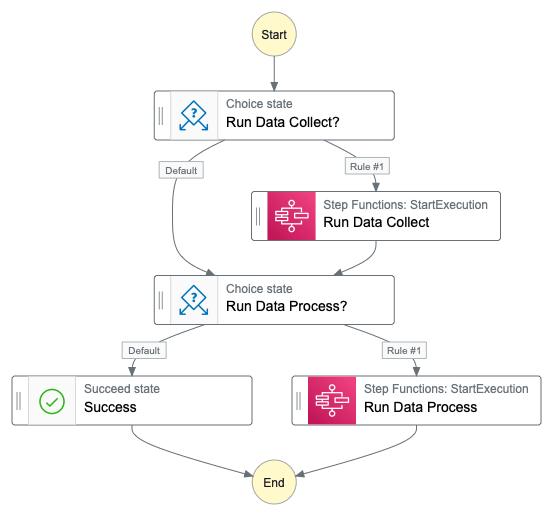
Why triggering a Step Function from a Step Function?
Easier debugging.
By decoupling collect and process and creating two child Step Functions it was easier to debug. I was able to run them workflows separately. It made the whole development process more friendly. On top of that, making changes in the underlying Step Functions doesn't affect the overall flow, and I can easily change the Step Function that is called.
Note on triggering Step Functions & CodeBuilds
My use-cases requires sequential execution of steps. By default, AWS Step Functions triggers another Step Function in, a "Fire and Forget", async manner. Meaning if the child Step Function trigger is successful, it proceeds to the next step.
My use-cases requires sequential execution of steps. By default, AWS Step Functions triggers another Step Function in, a "Fire and Forget", async manner. Meaning if the child Step Function trigger is successful, it proceeds to the next step.
To wait for the child Step Function execution to finish and return a Success(or Failure) state you should use
startExecution.sync. This ensures that the parent Step Function waits until the child Step Function finishes its work.Similarly for CodeBuild triggers. To wait for the build task to finish use
startBuild.sync.Note on environmental variable overrides in AWS Step Functions
Same code is used for all data collection and processing CodeBuild jobs. To make it possible I am passing environmental variables extensively to define parameters. I define them in Step Functions and use them as Docker
Same code is used for all data collection and processing CodeBuild jobs. To make it possible I am passing environmental variables extensively to define parameters. I define them in Step Functions and use them as Docker
--build-arg in CodeBuild.To make it work, I had to override the env vars in the Step Function CodeBuild trigger. This gave me a headache as AWS in their documentation Call AWS CodeBuild with Step Functions and API reference StartBuild says to use:
That's incorrect - see below. Notice the PascalCase instead of camelCase.
Collect Data
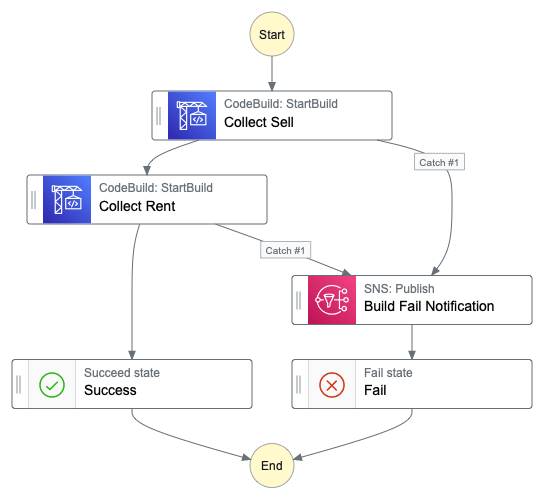
I use BeautifulSoup to collect data. There are great articles, and tutorials out there. I will only mention that I am running data collection sequentially to be a good internet citizen.
Process & Aggregate Data
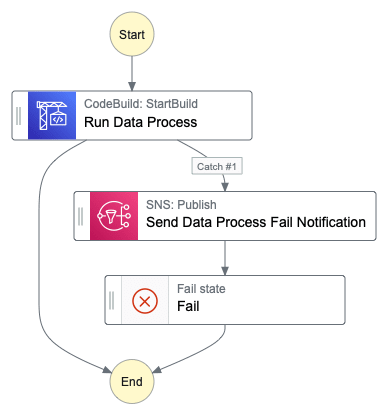
The magic happens inside of CodeBuild block where a Dagster pipeline is executed.
Dagster offers a number ways to deploy and execute pipelines. See here.
But that's not what I do - I run the Dagster in a Docker/CodeBuild. I am still questioning if it's the right approach. Nonetheless, taking the pipeline from local development to AWS was painless.

I mentioned that Dagster comes with an UI component - Dagit with a full suite of features to make development enjoyable. While I worked locally, I used both components. Dagit has great UI to launch pipelines, re-execute from a selected step, it also saves intermediary results, and keeps a DB of runs.
Dagit is not necessary to execute Dagster runs and I did not install it at all for Docker builds. Thanks to Poetry it was easy to separate dev installs and save time while building.

I must say that using Dagster might have been an overkill but this project was a great opportunity to learn it. Also provides future-proofness in case I want to restructure my project (add data collection to Dagster pipeline etc.), add machine learning pipelines to Dagster's repository, execute on Spark.
When doing my research, I ran into Kedro as one of the alternatives. While not used on this project I repurposed Kedro's Data Engineering convention. It works with "layers" for each stage of the data engineering pipeline. I am only using the first 3 layers - Raw, Intermediate, and Primary. As, I am not (yet) running any machine learning jobs.
| Stage | Description | Format |
|---|---|---|
| Raw | "Raw" data that is gathered in the "Data Gathering" step of the State machine is downloaded to this folder | txt |
| Intermediate | Cleaned "raw" data. At this stage redundant columns are removed. Data is cleaned, validated, and mapped. | csv |
| Primary | Aggregated data that will be consumed by the front-end. | csv |
The above stages and associated directories contain data after each group of tasks was executed. Output files from Raw, Intermediate, and Primary are uploaded to S3. Locally, I used them for debugging and sanity checks.
Dagster separates business logic from the execution. You can write the business logic inside the components and Dagster takes care of the orchestration. The underlying execution engine is abstracted away. It's possible to use Dagster's executor, Dask, Celery, etc.
Briefly
@op is unit of compute work to be done - it should be simple and written in functional style. Larger number of @op can be connected into a @graph for convenience. I connected mapping, cleaning, and validation steps into graphs. A logical grouping of ops based on job type. @job is a fully connected graph of @op and @graph units that can be triggered to process data.As I am processing both, rent and sell data, using the same
@op in the same job in parallel and reusing the @ops by aliasing them. See the gist below:Full dagster
@job.
A
@graph implementation in Dagster.When expanded in Dagit it looks like below.
@graph helps to group operations together and unclutter the UI compared to only op implementation. Furthermore you can test a full block of operations instead of testing an operation by operation.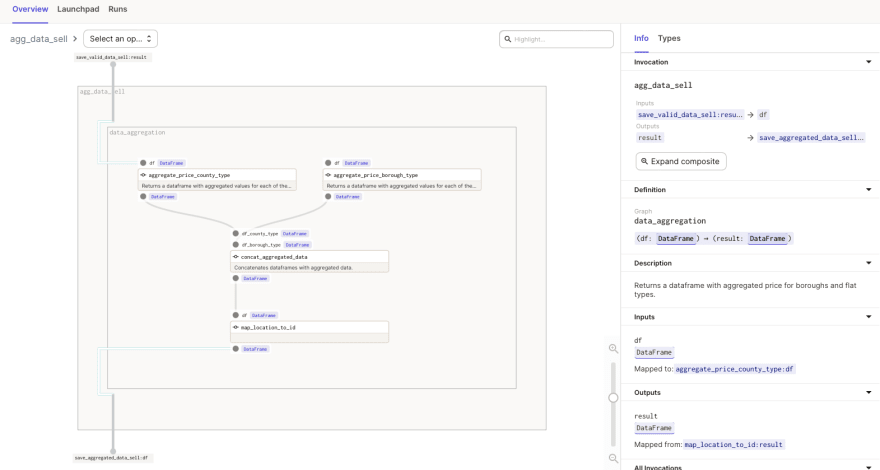
I finished the first version of my project. I already see how could parts of the code be improved. Mostly in the data processing part where I use Dagster. It's my first time working with this tool and I missed some important featrues that would make development, testing, and data handling easier.
dagster-aws model exists. Looking at the module it does exactly what I need, minus the code I had to write.@op. It's a legit approach but AssetMaterialization seems like a better, more Dagster-y, way to do it.Settings class which contained all settings and configs. In hindsight I should have added the Settings class to Dagster's context or just use Dagster's config. (I think I carried over the mindset from the previous pure-Python implementation of the data processing pipeline).Feel free to leave comment 📥 💫.
60