20
loading...

`pip install scrapy``scrapy startproject webscrawler`
#imports
import scrapy
#Spider class
class QuotesSpider(scrapy.Spider):
#name of your spider
name = "quotes"
def start_requests(self):
#Website links to crawl
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
#loop through the urls
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)scrapy crawl webscrawlerimport scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall()
}`scrapy crawl quotes -o results.json`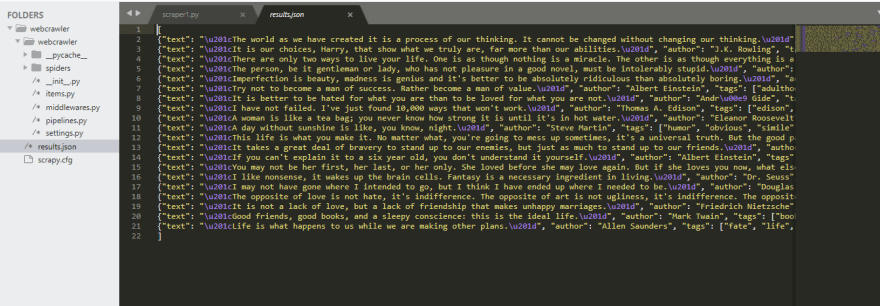
20