
40
Getting Started With Apache Airflow

Apache Airflow is another awesome tool that I discovered just recently. Just a couple of months after discovering it, I can’t imagine not using it now. It’s reliable, configurable, and dynamic. Because it’s all driven by code, you can version control it too. It’s just awesome! But wait, what the heck is Apache Airflow?
Apache Airflow is a workflow orchestration tool, to put it simply. Using Airflow, you can define the various steps involved in your workflow (data projects or not), define the relations between these various steps, and then schedule those steps as well. But wait, this sounds more like defining CRON jobs. You wouldn’t be entirely wrong there. But obviously, this is much more than just a fancy CRON job. Let’s dive deep and understand it.
The official definition of Airflow on it’s Apache homepage is:
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
That should give a high-level understanding of what Airflow is. Like most Apache projects, this is community driven and open source. It can be programmatically authored, which means you can write some code to not just define the workflow, but also to schedule and update it. As I already mentioned, you can have versioning on Airflow code and easily update or rollback the code at will. Oh, by the way, Airflow DAGs are written in Python.
Wait, what’s a DAG, you ask? DAG stands for Directed Acyclic Graph. This shouldn’t be new to you if you’ve already worked with tools such as Apache Spark. Spark jobs are internally converted to DAGs as well, which you can see visually from the web UI whenever a Spark job is running. Airflow uses the same concept to chain various operations together in a workflow.
Each operation in Airflow is defined using an operator. And of course, there are various operators. For example, in a DAG if you want to have an operation just to denote a virtual entity, you can use a DummyOperator. Similarly, if you want to run a execute a bash command or run a bash script file, you can use the BashOperator.
Similar to operators, there’s support for plugins as well, where you can integrate third party plugins to bring in more functionality to Airflow. Obviously you can write your own plugins as well. This should be fairly simple as writing a plugin is mostly as simple as writing a Python package. If you have experience with Python, you’d understand this looking at the documentation.
Another way to extend the functionality of Airflow is to use providers packages. This is different from plugins in the way that a providers package can include new operators, sensors, hooks, and transfer operators to extend Airflow. And as you can expect with any other popular open source platform, there are already a bunch of providers to provide a rich ecosystem. You can see the full list of current providers here.
Now that we understand at a very high level what Apache Airflow is, let’s look a simple example workflow to see how we can utilize Airflow.
Before we get started, if you are anything like me, you would want to have Airflow setup locally so that you can just copy-paste the code and see if it works. If this is you, you’d want to checkout the installation instructions, because there are a bunch of ways to install Airflow. Once you have Airflow up and running, make sure you switch from Derby to either MySQL or PostgreSQL as the backend database. This is because Derby gives some issues with scheduling DAGs and running them, even locally. You can see how to make the switch here. Don’t worry, it’s pretty simple and shouldn’t take more than a couple of minutes if you already have MySQL or Postgres already installed.
Even though the dataset itself isn’t important for this Airflow workflow, I just want to touch upon this dataset as this is one of the most frequently used dataset in the world of data science. The NYC Taxi and Limousine Commission (TLC) exposes each month’s taxi data as CSVs, for free. So I’m using that, well a sub-set of that. To be more specific, I’m using the yellow taxi data from December of 2020. You can get more info on this over here.
Finally, let’s get into the juicy bit. First, we need to define a DAG in our python file. This DAG, which is an instance of the DAG class, will be the identifier that tells Airflow that this particular file should be scanned and listed as a DAG in Airflow’s database. And this DAG taken in a bunch of default arguments which are literally called default arguments, I’m not even kidding. So let’s start by defining these default arguments:
default_args = {
'owner': 'sunny',
'depends_on_past': False,
'email': ['[email protected]'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}This should be pretty much self explanatory. I’m not going to talk much on each field in that object. Next, with this set of default arguments, we’ll define the DAG itself:
with DAG(
'load_nyc_taxi_data',
default_args=default_args,
description='DAG to load NYC Taxi data to Hive',
schedule_interval=timedelta(days=1),
start_date=days_ago(2),
tags=['sunny', 'sample'],
) as dag:The first argument to the DAG here is called the DAG ID. This, as you could imagine, is what uniquely identifies a DAG. The second argument is the set of default arguments that we defined in the previous step. The others are again pretty self explanatory.
The next step is to define the various operations that we want to perform in this workflow. So let’s talk about that first. For this example, I’m using Hive as the datastore for storing the yellow taxi data that I’m downloading. Why Hive? Well, why not? You can of course change any of all of this. Anyway, following is the operations that the DAG is going to perform, in the given order:
That’s pretty simple, right? Anyway, let’s look at each of these steps in detail.
This is a simple
create database query in Hive. But I’m not going to login to the Hive shell and then execute this query. Instead, I have written a .hql file that I’ll submit to the hive command, which will in turn execute the query that’s in the file. The .hql itself is pretty simple:create database if not exists nyc;I have this query in a file called
create_database.hql. And how exactly do I submit this to hive? That’s pretty simple too:hive -f /mnt/d/code/poc/airflow/create_database.hqlNow that we know what exactly we’re doing in this operation, let’s define a task in Airflow. We’ll use the BashOperator to create this task, as we’re running a bash command to perform this operation. The Python code to define this task is as follows:
create_database = BashOperator(
task_id='create_database',
bash_command='hive -f /mnt/d/code/poc/airflow/create_database.hql',
dag=dag
)The first argument to the BashOperator is a
task_id. This is the ID that will uniquely identify the task in the given DAG. So make sure you don’t have duplicate task IDs. The bash_command is the actual bash command that will be executed when Airflow triggers this task. That’s pretty much it for this task. Let’s move to the next task.Now that we have the database, let’s create a table to hold the NYC yellow taxi data. I have created this table definition based on the data in the CSV file that I downloaded from the source. So if you are using some other dataset, make sure to change the table definition accordingly.
Similar to the query for creating the database, I have the query for creating the table in a
.hql file called create_table.hql. The query itself is as follows:create table if not exists nyc.nyc_yellow_taxi_trips (
VendorID int,
tpep_pickup_datetime timestamp,
tpep_dropoff_datetime timestamp,
passenger_count int,
trip_distance double,
RatecodeID int,
store_and_fwd_flag string,
PULocationID int,
DOLocationID int,
payment_type int,
fare_amount double,
extra double,
mta_tax double,
tip_amount double,
tolls_amount double,
improvement_surcharge double,
total_amount double,
congestion_surcharge double
)
COMMENT 'NYC Yellow Taxi Trips'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';And the bash command to submit this query to Hive is also similar to the previous command:
hive -f /mnt/d/code/poc/airflow/create_table.hqlNext, let’s define the task in Airflow:
create_table = BashOperator(
task_id='create_table',
bash_command='hive -f /mnt/d/code/poc/airflow/create_table.hql',
dag=dag
)Nothing new here, this is very similar to the previous task, jus the task ID and the command are different. Next, we download the sample data.
You can skip this step if you want to manually download the CSV file. But because I’m automating a workflow, I thought it’ll be better if I made the download automated as well. In a real world workflow, getting the data for ingestion itself is a separate workflow. That’s another reason I wanted to have this as a task. Now, how am I downloading the dataset?
I’m using the
wget command to get the .csv file and place it in a path that I have already created. You don’t have to manually create the path because in most cases, the path will be constant. Anyway, the wget command itself is straightforward:wget https://nyc-tlc.s3.amazonaws.com/trip+data/yellow_tripdata_2020-12.csv -P /mnt/d/Backup/hive_sample_datasets/nyc_taxi_trips/nyc_yellow_taxi_trips/I have this command in a shell script called
download_dataset.sh. Now you might ask that because this is a bash command, and we have the BashOperator which can directly take the bash command, why are you creating a shell script to run this command? Valid question. Because we have a file for all the queries, I thought we’ll continue with that trend and create a file for this as well. You can directly use the bash command in the BashOperator itself. That should work the same way. Anyway, the task definition for this is:download_nyc_yellow_taxi_data = BashOperator(
task_id='download_nyc_yellow_taxi_data',
bash_command='/mnt/d/code/poc/airflow/download_dataset.sh ',
dag=dag
)At this stage, we have the database, the table, and the sample dataset. The only part pending is loading the data into Hive. This is another Hive query that I have written in another
.hql file called load_data_to_table.hql. The query itself is as follows:load data local inpath '/mnt/d/Backup/hive_sample_datasets/nyc_taxi_trips/nyc_yellow_taxi_trips/yellow_tripdata_2020-12.csv' into table nyc.nyc_yellow_taxi_trips;As you can see from the query, I’m loading the file from a local path. In a real world setup, you’d copy all the files to HDFS first and then load those files from HDFS to Hive. Because distributed, of course. You can do that here as well, but I didn’t see that adding to this demo. So I just skipped it. Now, the task definition for this step is:
load_data_to_table = BashOperator(
task_id='load_data_to_table',
bash_command='hive -f /mnt/d/code/poc/airflow/load_data_to_table.hql',
dag=dag
)We have all the tasks defined now. So let’s define the sequence of events now. Doing that is pretty simple. You’ll use the
>> operand to chain two tasks together. For example:task1 >> task2What this means is that when the Airflow DAG is triggered,
task1 will be executed first. Once that’s complete, task2 will be executed. This will happen in sequence. But what if you have another task, task3 that you want to trigger after task1 along with task2? You can do that in parallel like this:task1 >> task2
task1 >> task3In this case, as soon as
task1 is complete, tasks task2 and task3 will be executed in parallel. We don’t need this parallelism in our example though. For us, the sequence is as follows:start >> create_database >> create_table >> download_nyc_yellow_taxi_data >> load_data_to_table >> endWait, we only defined the four tasks in the middle. What are the start and end tasks? Glad that you asked. Those two are DummyOperators used to represent the start and the end of the workflow. You can use DummyOperators even in the middle of the workflow, basically wherever you want. But they do absolutely nothing more than adding a node in the DAG.
Now, if you open the Airflow web UI and open your DAG, you should see something similar to the following:

The green outline you see around each task indicates that the task completed successfully. If, for some reason, any of the task failed, you’d see a red outline around that task, like the example shown below:
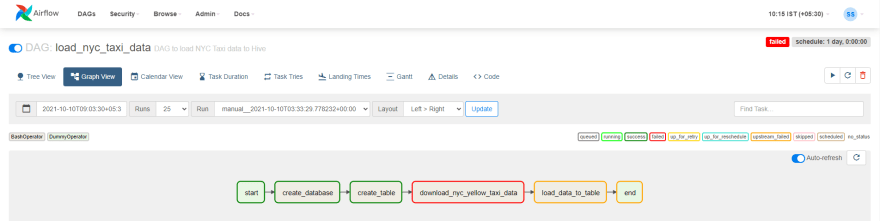
Running a DAG is pretty straightforward, at least for our example as we don’t have any schedule in place. At the top right corner of the Airflow web UI, you’ll see the trigger DAG button, which looks like a play button. Click on that, and you’ll get a couple of options. The first option is to trigger the DAG, and the second is to trigger the DAG with some options. We’ll not look at the second option for now. You can see this in the screenshot below:
Click the Tigger DAG option and you should see the DAG trigger now. But for this to happen, make sure you have enabled the DAG first. By default, when a new DAG is discovered by Airflow, it doesn’t enable it. You have to do that manually the first time. And enabling the DAG is pretty simple. At the top left corner of the Airflow web UI, where you see the DAG ID displayed in large font, you’ll see a toggle to the left of the DAG ID, as shown in the screenshot below.

That toggle will be off by default. Toggle it on to enable the DAG, it’s as simple as that. If you skip this step and trigger the DAG directly, Airflow will not throw a error or put up a notice that you have to enable it first. This is quite unfortunate, but do remember to do this for all new DAGs.
When you trigger a DAG, Airflow takes you the tree view by default. You can see the tree view for our sample DAG in the screenshot below. You can change this behavior to instead take you to the graph view, but that’s a preference you’ll have to discover for yourself. I prefer to stay in the graph view when I trigger a DAG. Because as the workflows get complex and you more tasks to it, it becomes difficult to understand which task is running in the tree view. Graph view is much easier, at least for me.

If a task fails, you can click on it to get a modal which will have the option to either restart the task and all downstream tasks from that point, or check the logs, or just mark it as a success. Once you start writing more complex workflows, you’ll get a chance to experiment with various features of the tool.
That’s pretty much it. If you want to look at the complete code base for this instead of stitching together all these pieces, have a look at my Github repo which has the same code. And if you think my understanding is wrong anywhere with Airflow, please leave a comment to make sure you correct me.
And if you like what you see here, or on my Medium blog and personal blog, and would like to see more of such helpful technical posts in the future, consider supporting me on Patreon and Github.
40