
52
Scrape Multiple Google Answer Box Layouts with Python
This blog post covers how to scrape: weather, stock, converter, calculator, phone number, address, population, translation, dictionary, matches, flights, formulas, and multiple organic layout answer box results using Python.
Note: Not every possible layout is covered here. Some of them may just not seen by me.
Contents:
Intro
You'll see usage of
if/elif/else, try/except, list comprehension, usage of zip() function. Simple stuff, but if you're a bit new to this, be sure to see what some of the things are doing since there won't be any proper explanation. An alternative API solution will be shown.Prerequisites
$ pip install requests
$ pip install lxml
$ pip install beautifulsoup4
$ pip install google-search-resultsMake sure you have a basic knowledge of libraries mentioned above (except google-search-results), since this blog post is not exactly a tutorial for beginners, so be sure you have a basic familiarity with them. I'll try my best to show in code that it's not that difficult.
Also, make sure you have a basic understanding of
CSS selectors because of select()/select_one() beautifulsoup methods which accepts CSS selectors. CSS selectors reference.Imports
import requests, lxml
from bs4 import BeautifulSoup
from serpapi import GoogleSearch # API soulutionScrape Google Phone Number Answer Box
There're several HTML layouts for phone answer box I stumble upon. All of this layouts will be scraped in the code below.




import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
test_queries = [
'skyscanner customer service phone number',
'ryanair phone number uk',
'wizz air phone number',
'apple online customer service phone number',
'amazon phone number',
'walmart online phone number',
'imb bank online phone number',
'target online phone number',
'yelp online phone number'
]
def get_phone_answer_box():
for query in test_queries:
params = {
"q": query,
"hl": "en",
"gl": "us"
}
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
# several CSS selectors to cover multiple layouts
phone_number = soup.select_one('.d9FyLd b, .IZ6rdc, .EfDVh, .mw31Ze, .hgKElc b').text
print(phone_number)
get_phone_answer_box()
-----------
'''
1-800-455-2720
+44 1279358438
0330 977 0444
(800) MY–APPLE (800–692–7753)
1 (206) 922-0880
1 (800) 925-6278
011 61 2 4227 9111
1 (800) 440-0680
(877) 767-9357
'''Scrape Google Calculator Answer Box
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "32*3/3+12*332-1995",
}
def get_calculator_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
math_expression = soup.select_one('.XH1CIc').text.strip().replace(' =', '')
calc_answer = soup.select_one('#cwos').text.strip()
print(f"Expression: {math_expression}\nAnswer: {calc_answer}")
get_calculator_answerbox()
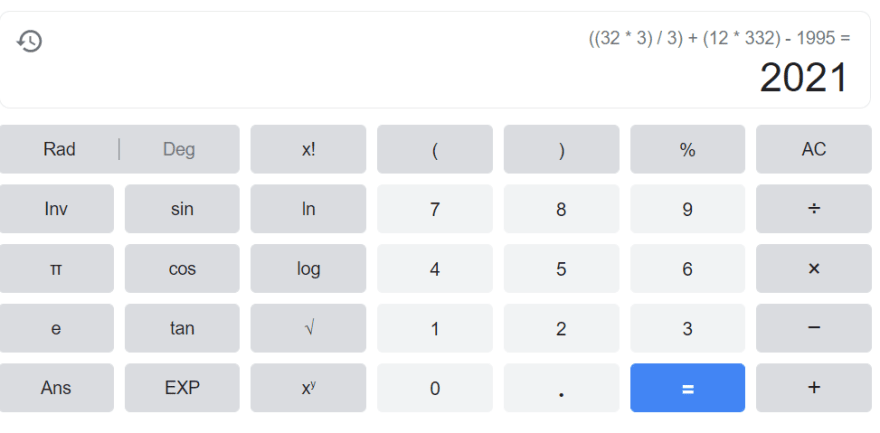
'''
Expression: ((32 * 3) / 3) + (12 * 332) - 1995
Answer: 2021
'''Scrape Google Weather Answer Box
from bs4 import BeautifulSoup
import requests, lxml
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "london weather", # query
"gl": "uk" # country to search from (United Kingdom)
}
def get_weather_answerbox():
response = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(response.text, 'lxml')
location = soup.select_one('#wob_loc').text
weather_condition = soup.select_one('#wob_dc').text
tempature = soup.select_one('#wob_tm').text
precipitation = soup.select_one('#wob_pp').text
humidity = soup.select_one('#wob_hm').text
wind = soup.select_one('#wob_ws').text
current_time = soup.select_one('#wob_dts').text
print(f'Location: {location}\n'
f'Weather condition: {weather_condition}\n'
f'Temperature: {tempature}°C\n'
f'Precipitation: {precipitation}\n'
f'Humidity: {humidity}\n'
f'Wind speed: {wind}\n'
f'Current time: {current_time}\n')
print('Forcast wind:')
for wind_speed_direction in soup.select('.wob_noe .wob_hw'):
try:
wind_speed = wind_speed_direction.select_one('.wob_t').text
'''
extracts elemenets, splits the string by a SPACE and grabs 2nd and 4th index,
and then joins via SPACE.
Example:
7 mph From northwest Sunday 9:00 AM ---> From northeast
'''
wind_direction = ' '.join(wind_speed_direction.select_one('.wob_t')['aria-label'].split(' ')[2:4])
print(f"Wind Speed: {wind_speed}\nWind Direction: {wind_direction}\n")
except:
pass # or return None instead
print('Forcast temperature:')
for forecast in soup.select('.wob_df'):
day = forecast.select_one('.Z1VzSb')['aria-label']
weather = forecast.select_one('img.uW5pk')['alt']
# check if selector exists in "current" HTML layout
if forecast.select_one('.vk_gy .wob_t:nth-child(1)') is None:
# different HTML layout selector
high_temp = forecast.select_one('.gNCp2e .wob_t').text
else:
# different HTML layout selector
high_temp = forecast.select_one('.vk_gy .wob_t:nth-child(1)').text
low_temp = forecast.select_one('.QrNVmd .wob_t:nth-child(1)').text
print(f'Day: {day}\nWeather: {weather}\nHigh: {high_temp}, Low: {low_temp}\n')
print("Forecast Precipitation:")
for recipitation_forecast in soup.select('.wob_hw'):
try:
recipitation = recipitation_forecast.select_one('.XwOqJe')['aria-label'].split(' ')[0]
except: recipitation = None
print(recipitation)
get_weather_answerbox()
---------
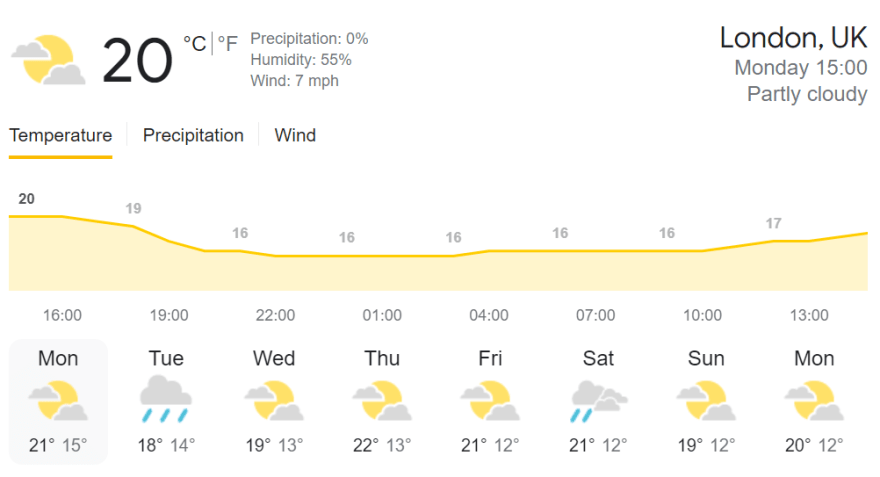
'''
Location: London, UK
Weather condition: Partly cloudy
Temperature: 20°C
Precipitation: 0%
Humidity: 55%
Wind speed: 7 mph
Current time: Monday 15:00
Forcast wind:
Wind Speed: 8 mph
Wind Direction: From east
...
Forcast temperature:
Day: Monday
Weather: Partly cloudy
High: 21, Low: 15
...
Forecast Precipitation:
0%
1%
1%
2%
2%
4%
12%
'''Scrape Google Stock Answer Box
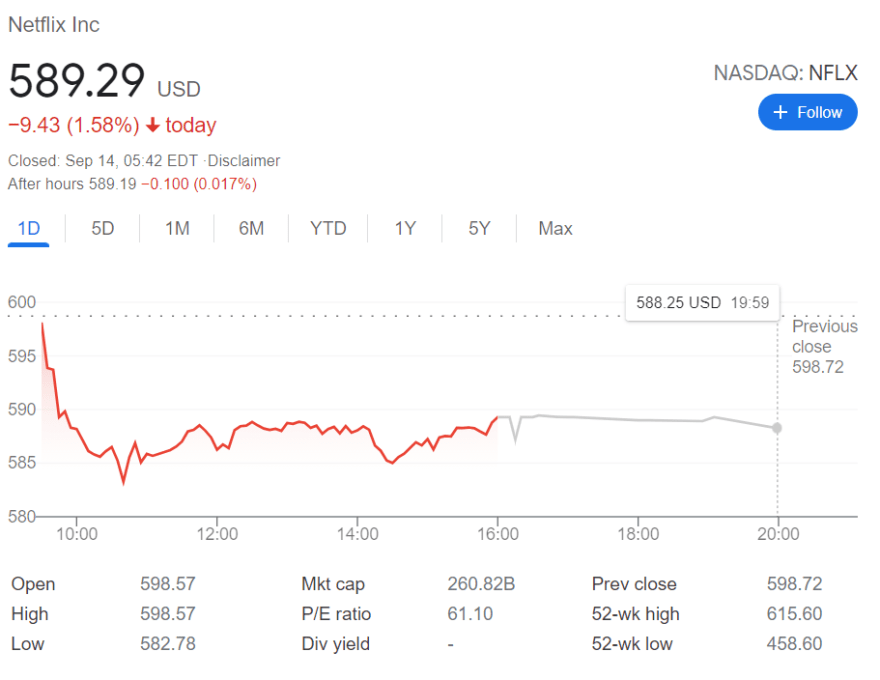
There are currently two layouts depending on the country from which the search was initiated (
'gl'='COUNTRY' query parameter): 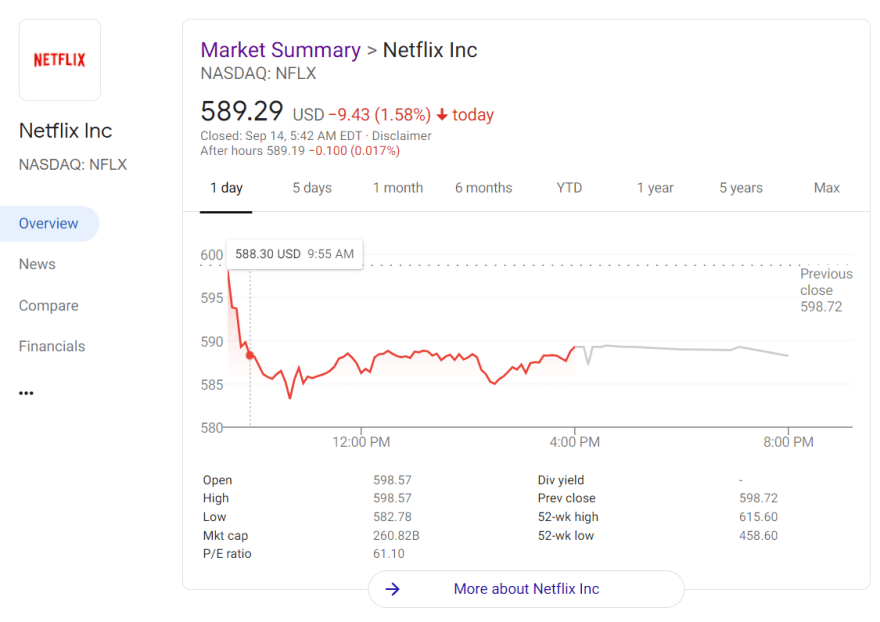
import requests, lxml
from bs4 import BeautifulSoup
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
stock_queries = [
'netflix stock',
'amazon stock',
'alibaba stock',
'cloudflare stock',
'apple stock',
'walmart stock'
]
def get_stock_answerbox():
for query in stock_queries:
params = {
'q': query,
'gl': 'us'
}
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
title = soup.select_one('.oPhL2e').text.replace(u'\xa0', u'').split('>')[1]
link = soup.select_one('.tiS4rf')['href']
date_time = soup.select_one('[jsname=ihIZgd]').text.replace(' ·', '')
market_status = soup.select_one('.TgMHGc span:nth-child(1)').text.strip().replace(':', '')
currency = soup.select_one('.knFDje').text.strip()
# two selectors which will handle two layouts
current_price = soup.select_one('.wT3VGc, .XcVN5d').text
price_change = soup.select_one('.WlRRw > span:nth-child(1)').text
price_change_percent = soup.select_one('.jBBUv span:nth-child(1)').text.replace('(', '').replace(')', '')
price_change_date = soup.select_one('.jdUcZd span').text.strip().capitalize()
price_movement = 'Down' if '−' in price_change else 'Up'
# different exchange & stock ticker layout handling (US website has a different stock layout)
if soup.select_one('.HfMth') is None:
exchange = soup.select_one('.EFkvDd').text
stock_ticker = soup.select_one('.WuDkNe').text
else:
stock_exchange_ticker = soup.select_one('.HfMth').text
exchange = stock_exchange_ticker.split(': ')[0]
stock_ticker = stock_exchange_ticker.split(': ')[1]
print(f'\nTitle: {title}\n'
f'Link: {link}\n'
f'Stock status: {market_status}\n'
f'Current time: {date_time}\n'
f'Exchange: {exchange}\n'
f'Stock ticker: {stock_ticker}\n'
f'Currency: {currency}\n'
f'Current price: {current_price}\n'
f'Price change: {price_change}\n'
f'Percent price change: {price_change_percent}\n'
f'Price movement: {price_movement}\n'
f'Price change date: {price_change_date}\n')
for stock_table_key, stock_table_value in zip(soup.select('.JgXcPd'), soup.select('.iyjjgb')):
stock_key = stock_table_key.text
stock_value = stock_table_value.text
print(f"{stock_key}: {stock_value}")
get_stock_answerbox()
-------------
'''
Title: Netflix Inc
Link: https://www.google.com/finance/quote/NFLX:NASDAQ?sa=X&ved=2ahUKEwj1npu7oP7yAhWEcc0KHT1uDiEQ3ecFegQIGxAS
Stock status: Closed
Current time: Sep 14, 5:42 AM EDT
Exchange: NASDAQ
Stock ticker: NFLX
Currency: USD
Current price: 589.29
Price change: −9.43
Percent price change: 1.58%
Price movement: Down
Price change date: Today
Open: 598.57
High: 598.57
Low: 582.78
Mkt cap: 260.82B
P/E ratio: 61.10
Div yield: -
Prev close: 598.72
52-wk high: 615.60
52-wk low: 458.60
Title: Amazon.com, Inc.
Link: https://www.google.com/finance/quote/AMZN:NASDAQ?sa=X&ved=2ahUKEwjeoOW7oP7yAhVRK80KHZoSCSEQ3ecFegQIKRAS
Stock status: Closed
Current time: Sep 13, 6:54 PM EDT
Exchange: NASDAQ
Stock ticker: AMZN
Currency: USD
Current price: 3,457.17
Price change: −11.98
Percent price change: 0.35%
Price movement: Down
Price change date: Today
Open: 3,482.80
High: 3,497.96
Low: 3,438.00
Mkt cap: 1.75T
P/E ratio: 60.25
Div yield: -
52-wk high: 3,773.08
52-wk low: 2,871.00
...
'''Scrape Google Population Answer Box

import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "population of london",
}
def get_population_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
place = soup.select_one('.GzssTd span').text
population_year = soup.select_one('.KBXm4e').text.split(' ')
population = population_year[0]
year = population_year[1].replace('(', '').replace(')', '')
explore_more_link = soup.select_one('.tiS4rf')['href']
sources = [source.text for source in soup.select('.kno-ftr span a')]
print(f'{place}\nCurrent population: {population}\nCaptured in {year}\n{sources}\n{explore_more_link}\n')
for other_city, other_population in zip(soup.select('.AleqXe'), soup.select('.kpd-lv')):
other_place_city = other_city.text.strip()
other_place_population = other_population.text
print(f'{other_place_city}: {other_place_population}')
get_population_answerbox()
-----------
'''
London
Current population: 8.982 million
Captured in 2019
['Eurostat', 'United States Census Bureau', 'Feedback']
https://datacommons.org/place?utm_medium=explore&dcid=nuts/UKI&mprop=count&popt=Person&hl=en
London: 8.982 million
New York: 8.419 million
Scotland: 5.454 million
'''Scrape Google Converter Answer Box
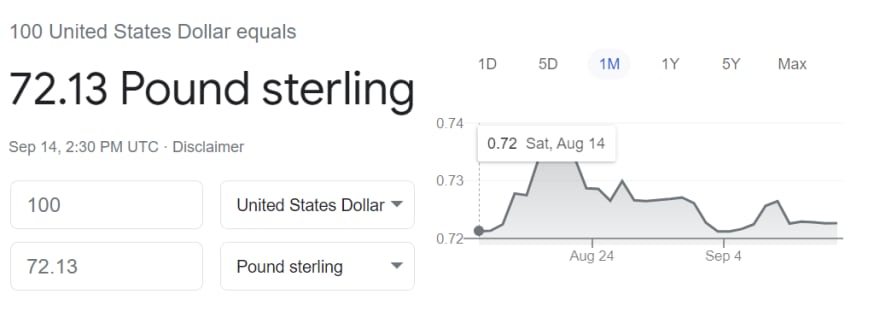
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "100 usd in gbp",
"gl": "us"
}
def get_converter_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
conversion = soup.select_one('.SwHCTb').text
conversion_currency = soup.select_one('.MWvIVe').text
print(f"{conversion} {conversion_currency}")
get_converter_answerbox()
# 72.16 Pound sterlingScrape Google Dictionary Answer Box
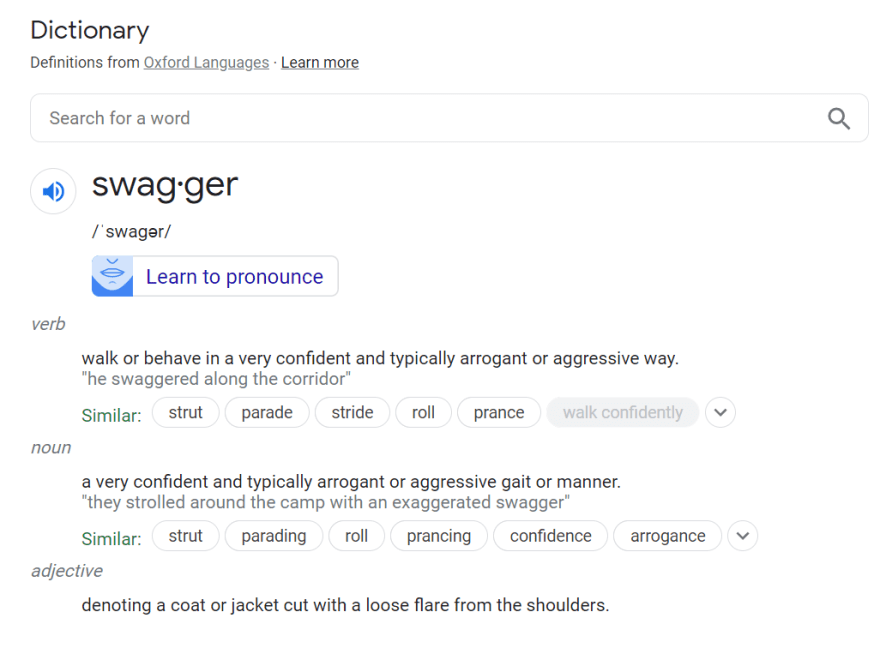
import requests, lxml
from bs4 import BeautifulSoup
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
params = {
'q': 'swagger definition',
'gl': 'us'
}
def get_dictionary_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
data = []
for result in soup.select('.VpH2eb.vmod'):
syllables = result.select_one('.DgZBFd span').text
audio_link = f"https:{result.select_one('.brWULd audio source')['src']}"
phonetic = result.select_one('.S23sjd .LTKOO span').text
word_types = [word_type.text for word_type in result.select('.vdBwhd .YrbPuc')]
definitions = [definition.text for definition in result.select('.LTKOO div[data-dobid=dfn]')]
sentence_examples = [example.text for example in result.select('.ubHt5c')]
similar_words = [similar_word.text for similar_word in result.select('.p9F8Cd span')]
data.append({
'syllables': syllables,
'audio_link': audio_link,
'phonetic': phonetic,
'examples': {
'word_type': [word_types],
'definitions': [definitions],
'sentence_examples': [sentence_examples],
'similar_words': [similar_words]
}
})
print(json.dumps(data, indent = 2, ensure_ascii = False))
get_dictionary_answerbox()
---------
'''
[
{
"syllables": "swag·ger",
"audio_link": "https://ssl.gstatic.com/dictionary/static/sounds/20200429/swagger--_us_1.mp3",
"phonetic": "ˈswaɡər",
"examples": {
"word_type": [
[
"verb",
"noun",
"adjective"
]
],
"definitions": [
[
"walk or behave in a very confident and typically arrogant or aggressive way.",
"a very confident and typically arrogant or aggressive gait or manner.",
"denoting a coat or jacket cut with a loose flare from the shoulders."
]
],
"sentence_examples": [
[
"\"he swaggered along the corridor\"",
"\"they strolled around the camp with an exaggerated swagger\""
]
],
"similar_words": [
[
"strut",
"parade",
"stride",
"roll",
"prance",
"sashay",
"swash",
"boast",
"brag",
"bray",
"bluster",
"crow",
"gloat",
"posture",
"pose",
"blow one's own trumpet",
"show off",
"swank",
"play to the gallery",
"rodomontade",
"strut",
"parading",
"roll",
"prancing",
"confidence",
"arrogance",
"self-assurance",
"show",
"ostentation",
"boasting",
"bragging",
"bluster",
"swashbuckling",
"vainglory",
"puffery",
"swank",
"braggadocio",
"rodomontade",
"gasconade"
]
]
}
}
]
'''Scrape Google First Organic Answer Box
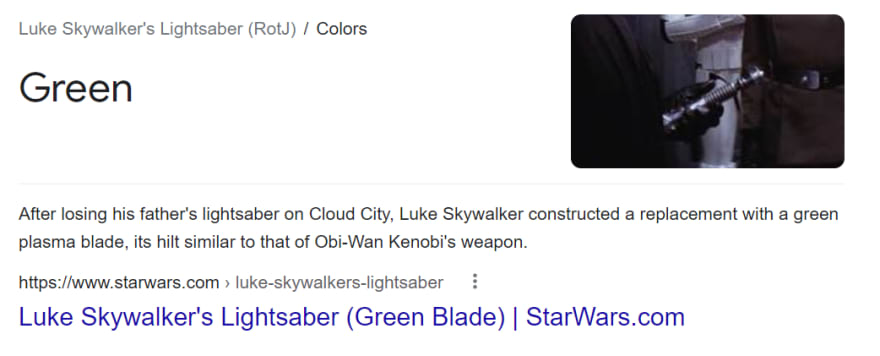

import requests, lxml
from bs4 import BeautifulSoup
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
params = {
'q': 'luke skywalker lightsaber color',
'gl': 'us'
}
def get_organic_result_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
answer = soup.select_one('.XcVN5d').text
title = soup.select_one('.DKV0Md').text
link = soup.select_one('.yuRUbf a')['href']
snippet = soup.select_one('.hgKElc').text
print(f"{answer}\n{title}\n{link}\n{snippet}")
get_organic_result_answerbox()
----------
'''
Green
Luke Skywalker's Lightsaber (Green Blade) | StarWars.com
https://www.starwars.com/databank/luke-skywalkers-lightsaber
After losing his father's lightsaber on Cloud City, Luke Skywalker constructed a replacement with a green plasma blade, its hilt similar to that of Obi-Wan Kenobi's weapon.
'''Scrape Google Second Organic Answer Box
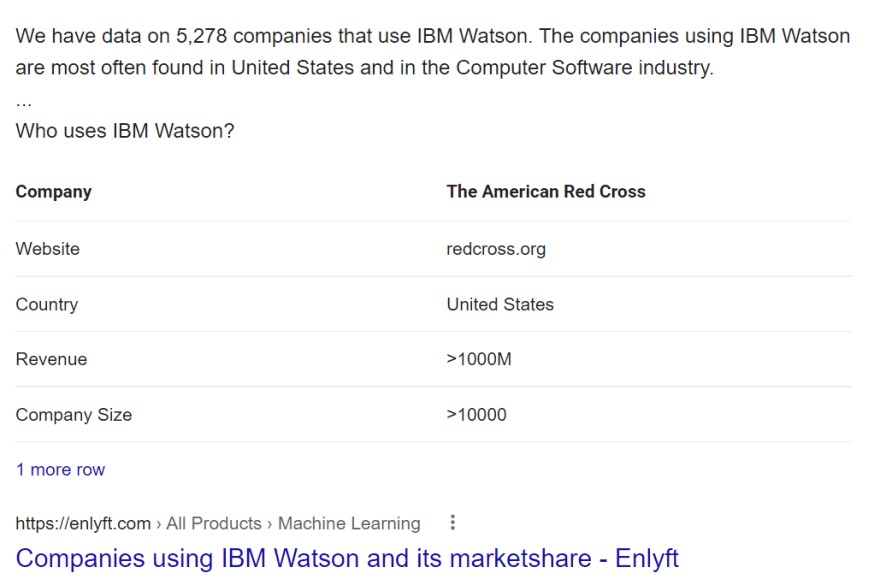

import requests, lxml
from bs4 import BeautifulSoup
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
params = {
'q': 'Who is using IBM',
'gl': 'us'
}
def get_second_organic_result_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
title = soup.select_one('.xpdopen .DKV0Md').text
link = soup.select_one('.xpdopen .yuRUbf a')['href']
displayed_link = soup.select_one('.xpdopen .iUh30').text
# snippet layout handling + bulletpoints
# example: shorturl.at/kIJQ9
if soup.select_one('.xpdopen .co8aDb b') and soup.select_one('.TrT0Xe') is not None:
snippet = soup.select_one('.xpdopen .co8aDb b').text
bullet_points = '\n'.join([bullet_point.text for bullet_point in soup.select('.TrT0Xe')])
else:
snippet = soup.select_one('.xpdopen .iKJnec').text
bullet_points = None
print(f'{title}\n{link}\n{displayed_link}\n{snippet}\n\nBullet points:\n{bullet_points}')
if soup.select_one('#rso td:nth-child(1)') is None:
pass
else:
print('\nTable:')
for table_key, table_value in zip(
soup.select('#rso td:nth-child(1)'),
soup.select('#rso td+ td')):
key = table_key.text
value = table_value.text
print(f'{key}: {value}')
get_second_organic_result_answerbox()
----------
'''
Companies using IBM Watson and its marketshare - Enlyft
https://enlyft.com/tech/products/ibm-watson
https://enlyft.com › All Products › Machine Learning
The companies using IBM Watson are most often found in United States and in the Computer Software industry. IBM Watson is most often used by companies with 10-50 employees and 1M-10M dollars in revenue....Who uses IBM Watson?
Website: redcross.org
Country: United States
Revenue: >1000M
Company Size: >10000
# second layout
Types of Content Writing - DemandJump
https://www.demandjump.com/blog/types-of-content-writing
https://www.demandjump.com › blog › types-of-conten...
What are the types of content writing?
Bullet points:
Blogging. Creating blog posts is a staple of content writing. ...
Copywriting. ...
Technical Writing/Long Form. ...
Social Media Posts. ...
Emails.
SEO Content Writer. An SEO writer is one of the most important content writer types out there. ...
Blog Content Writer. ...
Long-Form Content Writer. ...
Social Media Content Writer. ...
Copywriter. ...
Email Marketing Writer. ...
Technical Writers. ...
Press Release Writer.
'''Scrape Google Third Organic Answer Box

import requests, lxml
from bs4 import BeautifulSoup
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
params = {
'q': 'How much is a large pizza at Papa Johns',
'gl': 'us'
}
def get_third_organic_result_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
title = soup.select_one('.ifM9O .LC20lb').text
link = soup.select_one('.ifM9O .yuRUbf a')['href']
displayed_link = soup.select_one('.ifM9O .iUh30').text
snippet = soup.select_one('.ifM9O .iKJnec').text
print(title, link, displayed_link, snippet, sep='\n')
for table_key, table_value, table_value_price in zip(
soup.select('.ztXv9~ tr+ tr td:nth-child(1)'),
soup.select('td:nth-child(2)'),
soup.select('td~ td+ td')):
key = table_key.text
value = table_value.text
price = table_value_price.text
print(f"{key}: {value}, {price}")
get_third_organic_result_answerbox()
--------------
'''
Papa John's - Fast Food Menu Prices
https://www.fastfoodmenuprices.com/papa-johns-prices/
https://www.fastfoodmenuprices.com › papa-johns-prices
Papa John's Menu Prices
Cheese (Original): Medium, $13.00
Cheese (Original): Large, $15.00
Cheese (Original): Extra Large, $17.00
'''Scrape Google Translation Answer Box

import requests, lxml
from bs4 import BeautifulSoup
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
params = {
'q': 'hello in french',
'gl': 'us'
}
def get_translation_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
detected_language = soup.select_one('.source-language').text
text = soup.select_one('#tw-source-text-ta').text
pronounce = soup.select_one('#tw-source-rmn .Y2IQFc').text
target_language = soup.select_one('.target-language').text
target_text = soup.select_one('#tw-target-text .Y2IQFc').text
print(detected_language, text, pronounce, target_language, target_text, sep='\n')
for result in soup.select('.DFDLnc'):
title = result.next_sibling.select_one('.hrcAhc').text
words = result.next_sibling.select_one('.MaH2Hf').text
print(title, words, sep='\n')
get_translation_answerbox()
------------
'''
English - detected
hello
həˈlō
French
Bonjour
Bonjour!
Hello!, Hi!, Good morning!, Good afternoon!, How do you do?, Hallo!
Salut!
Hi!, Hello!, Salute!, All the best!, Hallo!, Hullo!
Tiens!
Hallo!, Hello!, Hullo!, Why!
Allô!
Hello!, Hullo!, Hallo!
'''Scrape Google Formula Answer Boxes
There're currently two layouts of formulas that I found, this and the one below. The first one is straightforward, the second one is a bit tricky.
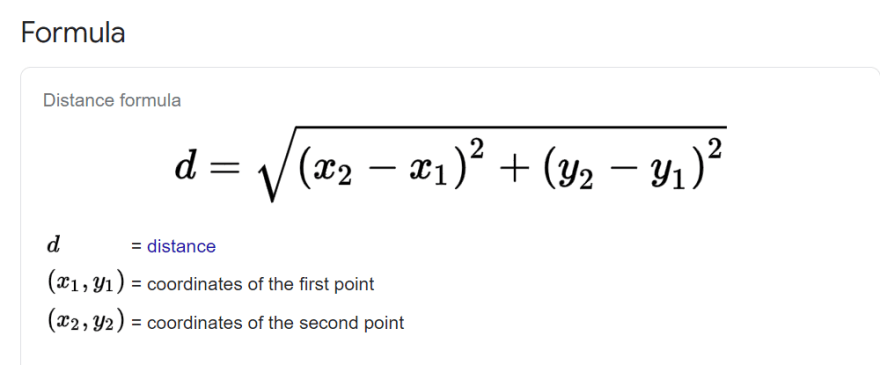
import requests, lxml, numpy, time
from bs4 import BeautifulSoup
from selenium import webdriver
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
params = {
'q': 'formula of distance',
'gl': 'us'
}
# example query: shorturl.at/euPX1
def get_formula_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
formula_img = soup.select_one('.IGEbUc')['src'].strip()
formula = soup.select_one('.IGEbUc')['alt']
print(formula, formula_img, sep='\n')
temp_list = []
clear_list = []
for symbol, definition in zip(
soup.select('img.ZFAGbf'),
soup.select('.GQLwEe')):
'''
appending to temporary list:
1. formula symbol name
2. formula symbol (plain text)
3. formula symbol image (svg)
'''
temp_list.append([definition.text, symbol['alt'], symbol['src']])
# https://stackoverflow.com/a/45323085/15164646
# multidimensional list -> flat list
for item in list(numpy.array(temp_list).flat):
if item not in clear_list:
clear_list.append(item)
for result in clear_list:
print(result)
get_formula_answerbox()
--------------
'''
d = \sqrt{(x_2 - x_1)^2 + (y_2-y_1)^2}
https://www.gstatic.com/education/formulas2/397133473/en/distance_formula.svg
distance
d
https://www.gstatic.com/education/formulas2/397133473/en/distance_formula_d.svg
coordinates of the first point
(x_1, y_1)
https://www.gstatic.com/education/formulas2/397133473/en/distance_formula_x1y1.svg
coordinates of the second point
(x_2, y_2)
https://www.gstatic.com/education/formulas2/397133473/en/distance_formula_x2y2.svg
'''The second layout is different because parsing such formulas (screenshot below) in such layout don't have
<img> option to scrape, instead, it's a plain text that doesn't make any sense. Note: Using
selenium slows down everything strong enough.
# example URL: shorturl.at/bfvAU
def get_formula_solve_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
if soup.select_one('#HE4HM') is not None:
title = soup.select_one('.vk_h').text
solving = soup.select_one('.goog-menu-button-caption').text
print(title, solving, sep='\n')
for i in soup.select('.lr-fy-ol.Gi02q'):
print(i.text)
else: print('no formula found')
# ----------------------------
# Another way using Selenium
driver = webdriver.Chrome(executable_path = 'path/to/chromedriver.exe')
CURRENT_DATE = time.strftime("%d/%m/%y")
queries = [
'volume of a cylinder',
'volume of a sphere',
'volume of a cone',
'volume of a cube',
'volume of a pyramid',
'sphere surface area',
'cube surface area'
]
for query in queries:
current_time = time.strftime("%H:%M:%S")
print(current_time)
driver.get(f"https://www.google.com/search?q={query}&gl=us")
plain_text_formula = driver.find_element_by_css_selector('.lr-fy-ol.Gi02q').text.replace('\n', '')
print(plain_text_formula)
driver.find_element_by_xpath('//*[@id="HE4HM"]/div/div[3]/div[2]').screenshot(f'formula_{CURRENT_DATE}_{current_time}.png')
time.sleep(1.3)
driver.quit()
get_formula_solve_answerbox()
----------
'''
# Bs4 output
Vπr2h
Va3
V43πr3
# Selenium output
V=πr2h
V=43πr3
V=πr2h3
V=a3
V=lwh3
A=4πr2
'''Screenshots from
Selenium:
And few examples of actual screenshots:




post request and send already taken screenshots.
import requests
import json
r = requests.post("https://api.mathpix.com/v3/text",
files={"file": open("YOUR_IMAGE_FILE.png","rb")},
data={
"options_json": json.dumps({
"math_inline_delimiters": ["$", "$"],
"rm_spaces": True
})
},
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY"
}
)
print(json.dumps(r.json(), indent=4, sort_keys=True))Get response:
{
"auto_rotate_confidence": 0.0046418966250847404,
"auto_rotate_degrees": 0,
"confidence": 0.9849104881286621,
"confidence_rate": 0.9849104881286621,
"is_handwritten": true,
"is_printed": false,
"latex_styled": "f(x)=\\left\\{\\begin{array}{ll}\nx^{2} & \\text { if } x<0 \\\\\n2 x & \\text { if } x \\geq 0\n\\end{array}\\right.",
"request_id": "bd02af63ef187492c085331c60151d98",
"text": "$f(x)=\\left\\{\\begin{array}{ll}x^{2} & \\text { if } x<0 \\\\ 2 x & \\text { if } x \\geq 0\\end{array}\\right.$"
}
...Note: possibly using
mathpix will be enough for your task, but if it's not, use Wolfram Alpha instead, this is their subject area of expertise.Scrape Google Flights Answer Boxes
import requests, lxml
from bs4 import BeautifulSoup
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
params = {
'q': 'flight from london to new york',
'gl': 'us'
}
def get_flights_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
title = soup.select_one('.N00E5e .mfMhoc').text.strip()
print(f"{title}\n")
for flight in soup.select('.ikUyY'):
link = flight['href']
airline = flight.select_one('.ps0VMc').text.strip()
flight_duration = flight.select_one('.sRcB8').text.strip()
flight_option = flight.select_one('.u85UCd').text.strip()
price = flight.select_one('.xqqLDd').text.strip()
print(f'{airline}\n{flight_duration}\n{flight_option}\n{price}\n{link}\n')
get_flights_answerbox()
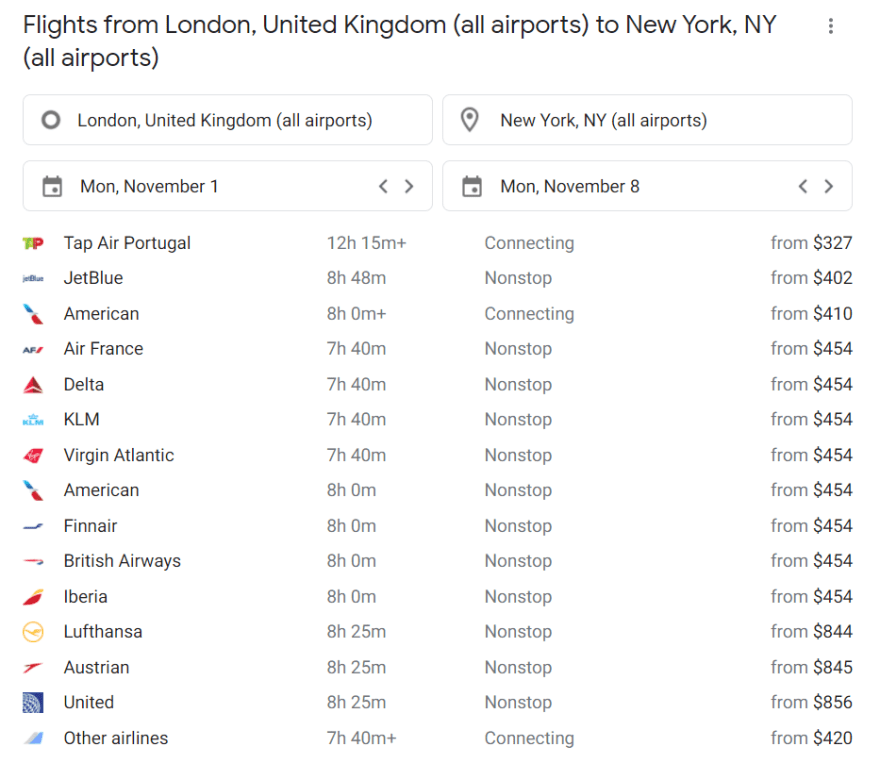
-----------
'''
Flights from London, United Kingdom (all airports) to New York, NY (all airports)
Tap Air Portugal
12h 15m+
Connecting
from $327
https://www.google.com/flights?gl=us&source=flun&uitype=cuAA&hl=en&curr=USD&tfs=CAEQAhotEgoyMDIxLTExLTAxMgJUUGoMCAISCC9tLzA0anBscg0IAhIJL20vMDJfMjg2Gi0SCjIwMjEtMTEtMDgyAlRQag0IAhIJL20vMDJfMjg2cgwIAhIIL20vMDRqcGx6aENqUklXbkpCZDA1WmRFeENRbTlCUmpnMVRIZENSeTB0TFMwdExTMHRMVzkxYldjeE9FRkJRVUZCUjBaQ2NtaEZSMDU1VDBGQkVnTmpWRkFhQ3dpOC93RVFBaG9EVlZORU9BTnd2UDhC&sa=X&ved=2ahUKEwjXrLmSx4DzAhWQGs0KHZZVAQYQ1RUoAHoECBcQGg
JetBlue
8h 48m
Nonstop
from $402
https://www.google.com/flights?gl=us&source=flun&uitype=cuAA&hl=en&curr=USD&tfs=CAEQAhotEgoyMDIxLTExLTAxMgJCNmoMCAISCC9tLzA0anBscg0IAhIJL20vMDJfMjg2Gi0SCjIwMjEtMTEtMDgyAkI2ag0IAhIJL20vMDJfMjg2cgwIAhIIL20vMDRqcGx6aENqUklXbkpCZDA1WmRFeENRbTlCUmpnMVRIZENSeTB0TFMwdExTMHRMVzkxYldjeE9FRkJRVUZCUjBaQ2NtaEZSMDU1VDBGQkVnTnVRallhQ3dpSXVnSVFBaG9EVlZORU9BTndpTG9D&sa=X&ved=2ahUKEwjXrLmSx4DzAhWQGs0KHZZVAQYQ1RUoAXoECBcQGw
...
'''Scrape Google Matches Answer Boxes

import requests, lxml
from bs4 import BeautifulSoup
headers = {
'User-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582'
}
params = {
'q': 'nfl matches',
'gl': 'us'
}
'''
Properly working while each team has scores, for example:
Chiefs: 29
Browns: 29
But when only date and time is shown it won't scrape it, for example:
Today
20:10
It would only scrape team which HAVE scores but the scores attached to teams won't be correct.
'''
def get_sport_matches_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
title = soup.select_one('.ofy7ae').text
if soup.select_one('.mKwiob'):
league = soup.select_one('.mKwiob').text
else: league = 'Not mentioned'
print(title, league, sep='\n')
print()
# zip() will get data in parallel but it will find all needed elements at once
for first_team, second_team, first_score, second_score, status, match_date, video_highlight in zip(
soup.select('.L5Kkcd+ .L5Kkcd span'),
soup.select('.L5Kkcd:nth-child(5) span'),
soup.select('.L5Kkcd:nth-child(5) .imspo_mt__t-sc .imspo_mt__tt-w'),
soup.select('.imspo_mt__lt-t .imspo_mt__tt-w'),
soup.select('.imspo_mt__match-status'),
soup.select('.imspo_mt__ms-w div div :nth-child(1)'),
soup.select('.BbrjBe')):
match_status = status.text
match_game_date = match_date.text
match_video_highlight = video_highlight.select_one('a')['href']
print(match_status, match_game_date, match_video_highlight, sep='\n')
print(f"{first_team.text}: {first_score.text}")
print(f"{second_team.text}: {second_score.text}")
print()
get_sport_matches_answerbox()
----------
'''
NFL
Week 1 of 18
Final
Sun, Sep 12
https://www.youtube.com/watch?v=4g2R-kn_-0c&feature=onebox
Chiefs: 29
Browns: 29
Final
Sun, Sep 12
https://www.youtube.com/watch?v=dc_e6GdLzls&feature=onebox
Patriots: 17
Dolphins: 16
...
'''Scrape Google Address Answer Box

import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "spotlight 29 casino address",
}
def get_address_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
address = soup.select_one('.sXLaOe').text
print(address)
get_address_answerbox()
# 46-200 Harrison Pl, Coachella, CA 92236Scrape Google Age Answer Box

import requests, lxml, json
from bs4 import BeautifulSoup
headers = {
"User-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "selena gomez age",
}
def get_age_answerbox():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
data = []
age = soup.select_one('.XcVN5d').text
birth_date = soup.select_one('.kZ91ed').text
people_also_search_for = [{
"title": search.select_one('.rOVRL').text,
"link": f"https://www.google.com{search.select_one('a')['href']}",
"age": search.select_one('.C9iYEe').text
} for search in soup.select('.PZPZlf.lLRSIb')]
data.append({
"age": age,
"birth_date": birth_date,
"people_also_search_for": people_also_search_for
})
print(json.dumps(data, indent=2, ensure_ascii=False))
---------
'''
[
{
"age": "29 years",
"birth_date": "July 22, 1992",
"people_also_search_for": [
{
"title": "Justin Bieber",
"link": "https://www.google.com/search?q=justin+bieber+age&stick=H4sIAAAAAAAAAONgFuLUz9U3SC82KytS4gIxzcqNivNMtfgCUouK8_OCM1NSyxMrixcximYnW-kXpOYX5KQCKZCcVWJ66iJWwazS4pLMPIWkzNSk1CIFoBgAbN1xHFUAAAA&sa=X&ved=2ahUKEwjdp4aN9N3zAhXHGs0KHUzUAEEQxA16BAgmEAQ",
"age": "27 years"
},
{
"title": "Ariana Grande",
"link": "https://www.google.com/search?q=ariana+grande+age&stick=H4sIAAAAAAAAAONgFuLUz9U3SC82KytS4gIxLdOzUypNtPgCUouK8_OCM1NSyxMrixcximYnW-kXpOYX5KQCKZCcVWJ66iJWwcSizMS8RIX0osS8lFQFoBgASMcE2FUAAAA&sa=X&ved=2ahUKEwjdp4aN9N3zAhXHGs0KHUzUAEEQxA16BAgmEAY",
"age": "28 years"
},
{
"title": "Taylor Swift",
"link": "https://www.google.com/search?q=taylor+swift+age&stick=H4sIAAAAAAAAAONgFuLUz9U3SC82KytSAjNTckzNzLX4AlKLivPzgjNTUssTK4sXMYpmJ1vpF6TmF-SkAimQnFVieuoiVoGSxMqc_CKF4vLMtBIFoBAA8NTXJlMAAAA&sa=X&ved=2ahUKEwjdp4aN9N3zAhXHGs0KHUzUAEEQxA16BAgmEAg",
"age": "31 years"
}
]
}
]
'''Scrape Google Answer Box Using SerpApi
SerpApi is a paid API with a free plan.
The difference is that everything (except the second formula layout) that was done above and more is already present by default and there's no need to maintain the parser over time if something in the HTML layout will be changed thus break the parser.
Instead, the only thing that really needs to be done is to iterate over structured JSON and get the data you want fast.
Example code for all mentioned layouts except the second formula layout:
from serpapi import GoogleSearch
import os, json
def serpapi_answerbox_example():
params = {
"api_key": os.getenv("API_KEY"), # API key environment
"engine": "google", # search engine
"q": "flight from london to new york", # query
"location": "United States", # from where search to originate
"google_domain": "google.com", # domain name
"gl": "us", # location to search from
"hl": "en" # language
}
search = GoogleSearch(params)
results = search.get_dict()
print(json.dumps(results['answer_box'], indent = 2, ensure_ascii = False))
-----------
'''
{
"type": "google_flights",
"title": "Flights from London, United Kingdom (all airports) to New York, NY (all airports)",
"flights": [
{
"link": "https://www.google.com/flights?gl=us&hl=en&source=flun&uitype=cuAA&curr=USD&tfs=CAEQAhotEgoyMDIxLTExLTAxMgJUUGoMCAISCC9tLzA0anBscg0IAhIJL20vMDJfMjg2Gi0SCjIwMjEtMTEtMDgyAlRQag0IAhIJL20vMDJfMjg2cgwIAhIIL20vMDRqcGx6aENqUklZVzVMZWtNM1YzVXhhVFJCUmpObGJHZENSeTB0TFMwdExTMHRMUzF2ZFhSa04wRkJRVUZCUjBaRE0wOWpURzFVYjBGQkVnTmpWRkFhQ3dpOC93RVFBaG9EVlZORU9BTnd2UDhC&sa=X&ved=2ahUKEwir8vL554LzAhUVnWoFHbhSAnAQ1RUoAHoECBYQGg",
"flight_info": [
"Tap Air Portugal",
"12h 15m+",
"Connecting",
"from $327"
]
},
{
"link": "https://www.google.com/flights?gl=us&hl=en&source=flun&uitype=cuAA&curr=USD&tfs=CAEQAhotEgoyMDIxLTExLTAxMgJCNmoMCAISCC9tLzA0anBscg0IAhIJL20vMDJfMjg2Gi0SCjIwMjEtMTEtMDgyAkI2ag0IAhIJL20vMDJfMjg2cgwIAhIIL20vMDRqcGx6aENqUklZVzVMZWtNM1YzVXhhVFJCUmpObGJHZENSeTB0TFMwdExTMHRMUzF2ZFhSa04wRkJRVUZCUjBaRE0wOWpURzFVYjBGQkVnTnVRallhQ3dpSXVnSVFBaG9EVlZORU9BTndpTG9D&sa=X&ved=2ahUKEwir8vL554LzAhUVnWoFHbhSAnAQ1RUoAXoECBYQGw",
"flight_info": [
"JetBlue",
"8h 48m",
"Nonstop",
"from $402"
]
}
]
}
'''Links
Outro
If you have any questions or something isn't working correctly or you have any suggestions, feel free to drop a comment in the comment section or via Twitter at @serp_api. If you found a bug using SerpApi, please, add this bug on SerpApi Forum.
Yours,
Dimitry, and the rest of SerpApi Team.
Dimitry, and the rest of SerpApi Team.
52