
46
How To Build a Soccer Data Web Scraper with Django and Fauna
In this tutorial, we will be extracting data from the top 5 soccer leagues globally: the EPL, La Liga, Serie A, Bundesliga, and Ligue 1. However, to obtain this data, we will be extracting it from an official sports website (understat.com). We will then learn how to store and manage these data with Fauna.
To fully understand this tutorial, you are required to have the following in place:
With the above prerequisites out of the way, we can now begin building our web scraper application.
Fauna is a client-side serverless database that uses GraphQL and the Fauna Query Language (FQL) to support various data types and relational databases in a serverless API. You can learn more about Fauna in their official documentation here. If this is the first time you have heard about Fauna, visit my previous article here for a brief introduction.
The libraries required for this tutorial are as follows:
To install the libraries required for this tutorial, run the following commands below:
pip install numpy
pip install pandas
pip install requests
pip install bs4Now that we have all the required libraries installed, let’s get to building our web scraper.
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import jsonThe first step in any web scraping project is researching the web page you want to scrape and learn how it works. That is critical to finding where to get the data from the site; therefore, this is where we’ll begin.

We can see on the home page that the site has data for six European leagues. However, we will be extracting data for just the top 5 leagues(teams excluding RFPL).

We can also notice that data on the site starts from 2014/2015 to 2020/2021. Let’s create variables to handle only the information we require.
# create urls for all seasons of all leagues
base_url = 'https://understat.com/league'
leagues = ['La_liga', 'EPL', 'Bundesliga', 'Serie_A', 'Ligue_1']
seasons = ['2016', '2017', '2018', '2019', '2020']The next step is to figure out where the data on the web page is stored. To do so, open Developer Tools in Chrome, navigate to the Network tab, locate the data file (in this example, 2018), and select the “Response” tab. After executing requests, this is what we'll get. get(URL)
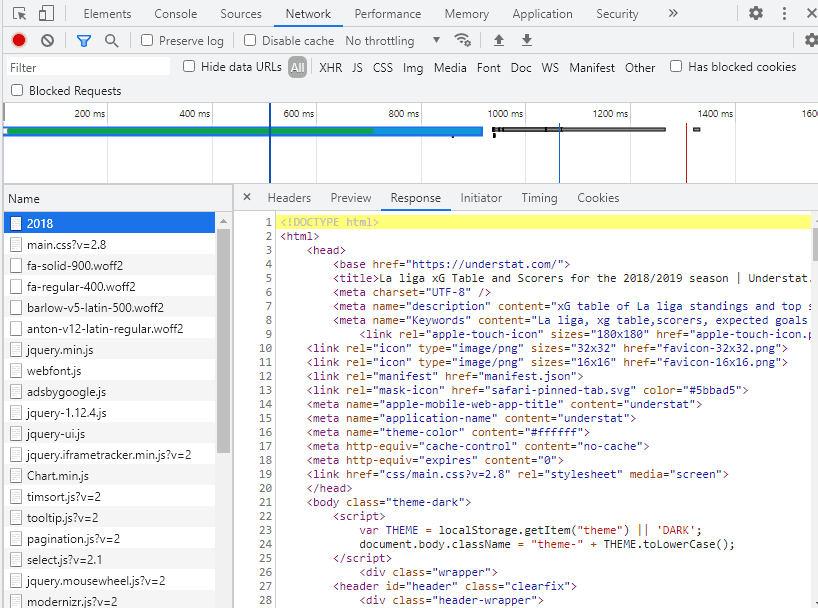
After looking through the web page's content, we discovered that the data is saved beneath the "script" element in the
teamsData variable and is JSON encoded. As a result, we'll need to track down this tag, extract JSON from it, and convert it to a Python-readable data structure.
season_data = dict()
for season in seasons:
url = base_url+'/'+league+'/'+season
res = requests.get(url)
soup = BeautifulSoup(res.content, "lxml")
# Based on the structure of the webpage, I found that data is in the JSON variable, under <script> tags
scripts = soup.find_all('script')
string_with_json_obj = ''
# Find data for teams
for el in scripts:
if 'teamsData' in str(el):
string_with_json_obj = str(el).strip()
# strip unnecessary symbols and get only JSON data
ind_start = string_with_json_obj.index("('")+2
ind_end = string_with_json_obj.index("')")
json_data = string_with_json_obj[ind_start:ind_end]
json_data = json_data.encode('utf8').decode('unicode_escape')
#print(json_data)After running the python code above, you should get data that we’ve cleaned up.
When we start looking at the data, we realise it's a dictionary of dictionaries with three keys: id, title, and history. Ids are also used as keys in the dictionary's initial layer.
Therefore, we can deduce that history has information on every match a team has played in its league (League Cup or Champions League games are omitted).
After reviewing the first layer dictionary, we can begin to compile a list of team names.
# Get teams and their relevant ids and put them into separate dictionary
teams = {}
for id in data.keys():
teams[id] = data[id]['title']We see that column names frequently appear; therefore, we put them in a separate list. Also, look at how the sample values appear.
columns = []
# Check the sample of values per each column
values = []
for id in data.keys():
columns = list(data[id]['history'][0].keys())
values = list(data[id]['history'][0].values())
breakNow let’s get data for all teams. Uncomment the print statement in the code below to print the data to your console.
# Getting data for all teams
dataframes = {}
for id, team in teams.items():
teams_data = []
for row in data[id]['history']:
teams_data.append(list(row.values()))
df = pd.DataFrame(teams_data, columns=columns)
dataframes[team] = df
# print('Added data for {}.'.format(team))After you have completed this code, we will have a dictionary of DataFrames with the key being the team's name and the value being the DataFrame containing all of the team's games.
When we look at the DataFrame content, we can see that metrics like PPDA and OPPDA (ppda and ppda allowed) are represented as total sums of attacking/defensive actions.
However, they are shown as coefficients in the original table. Let's clean that up.
for team, df in dataframes.items():
dataframes[team]['ppda_coef'] = dataframes[team]['ppda'].apply(lambda x: x['att']/x['def'] if x['def'] != 0 else 0)
dataframes[team]['oppda_coef'] = dataframes[team]['ppda_allowed'].apply(lambda x: x['att']/x['def'] if x['def'] != 0 else 0)We now have all of our numbers, but for every game. The totals for the team are what we require. Let's look at the columns we need to add up. To do so, we returned to the original table on the website and discovered that all measures should be added together, with only PPDA and OPPDA remaining as means in the end. First, let’s define the columns we need to sum and mean.
cols_to_sum = ['xG', 'xGA', 'npxG', 'npxGA', 'deep', 'deep_allowed', 'scored', 'missed', 'xpts', 'wins', 'draws', 'loses', 'pts', 'npxGD']
cols_to_mean = ['ppda_coef', 'oppda_coef']Finally, let’s calculate the totals and means.
for team, df in dataframes.items():
sum_data = pd.DataFrame(df[cols_to_sum].sum()).transpose()
mean_data = pd.DataFrame(df[cols_to_mean].mean()).transpose()
final_df = sum_data.join(mean_data)
final_df['team'] = team
final_df['matches'] = len(df)
frames.append(final_df)
full_stat = pd.concat(frames)
full_stat = full_stat[['team', 'matches', 'wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'xG', 'npxG', 'xGA', 'npxGA', 'npxGD', 'ppda_coef', 'oppda_coef', 'deep', 'deep_allowed', 'xpts']]
full_stat.sort_values('pts', ascending=False, inplace=True)
full_stat.reset_index(inplace=True, drop=True)
full_stat['position'] = range(1,len(full_stat)+1)
full_stat['xG_diff'] = full_stat['xG'] - full_stat['scored']
full_stat['xGA_diff'] = full_stat['xGA'] - full_stat['missed']
full_stat['xpts_diff'] = full_stat['xpts'] - full_stat['pts']
cols_to_int = ['wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'deep', 'deep_allowed']
full_stat[cols_to_int] = full_stat[cols_to_int].astype(int)In the code above, we reordered columns for better readability, sorted rows based on points, reset the index, and added column ‘position’.
We also added the differences between the expected metrics and real metrics.
Lastly, we converted the floats to integers where appropriate.
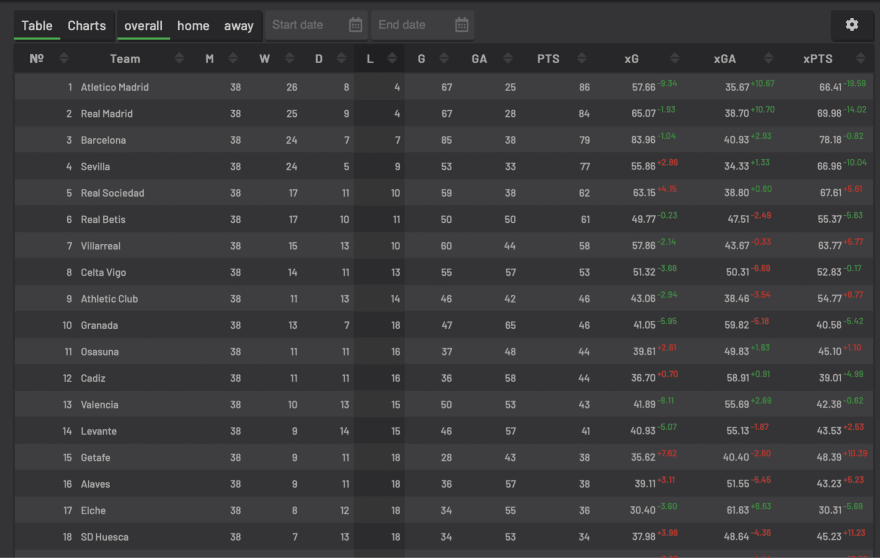
Finally, let’s beautify our data to become similar to the site data in the image above. To do this, run the python code below.
col_order = ['position', 'team', 'matches', 'wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'xG', 'xG_diff', 'npxG', 'xGA', 'xGA_diff', 'npxGA', 'npxGD', 'ppda_coef', 'oppda_coef', 'deep', 'deep_allowed', 'xpts', 'xpts_diff']
full_stat = full_stat[col_order]
full_stat = full_stat.set_index('position')
# print(full_stat.head(20))To print a part of the beautified data, uncomment the print statement in the code above.
To get all the data, we need to loop through all the leagues and seasons then manipulate it to be exportable as a CSV file.
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import json
# create urls for all seasons of all leagues
base_url = 'https://understat.com/league'
leagues = ['La_liga', 'EPL', 'Bundesliga', 'Serie_A', 'Ligue_1']
seasons = ['2016', '2017', '2018', '2019', '2020']
full_data = dict()
for league in leagues:
season_data = dict()
for season in seasons:
url = base_url+'/'+league+'/'+season
res = requests.get(url)
soup = BeautifulSoup(res.content, "lxml")
# Based on the structure of the webpage, I found that data is in the JSON variable, under <script> tags
scripts = soup.find_all('script')
string_with_json_obj = ''
# Find data for teams
for el in scripts:
if 'teamsData' in str(el):
string_with_json_obj = str(el).strip()
# print(string_with_json_obj)
# strip unnecessary symbols and get only JSON data
ind_start = string_with_json_obj.index("('")+2
ind_end = string_with_json_obj.index("')")
json_data = string_with_json_obj[ind_start:ind_end]
json_data = json_data.encode('utf8').decode('unicode_escape')
# convert JSON data into Python dictionary
data = json.loads(json_data)
# Get teams and their relevant ids and put them into separate dictionary
teams = {}
for id in data.keys():
teams[id] = data[id]['title']
# EDA to get a feeling of how the JSON is structured
# Column names are all the same, so we just use first element
columns = []
# Check the sample of values per each column
values = []
for id in data.keys():
columns = list(data[id]['history'][0].keys())
values = list(data[id]['history'][0].values())
break
# Getting data for all teams
dataframes = {}
for id, team in teams.items():
teams_data = []
for row in data[id]['history']:
teams_data.append(list(row.values()))
df = pd.DataFrame(teams_data, columns=columns)
dataframes[team] = df
# print('Added data for {}.'.format(team))
for team, df in dataframes.items():
dataframes[team]['ppda_coef'] = dataframes[team]['ppda'].apply(lambda x: x['att']/x['def'] if x['def'] != 0 else 0)
dataframes[team]['oppda_coef'] = dataframes[team]['ppda_allowed'].apply(lambda x: x['att']/x['def'] if x['def'] != 0 else 0)
cols_to_sum = ['xG', 'xGA', 'npxG', 'npxGA', 'deep', 'deep_allowed', 'scored', 'missed', 'xpts', 'wins', 'draws', 'loses', 'pts', 'npxGD']
cols_to_mean = ['ppda_coef', 'oppda_coef']
frames = []
for team, df in dataframes.items():
sum_data = pd.DataFrame(df[cols_to_sum].sum()).transpose()
mean_data = pd.DataFrame(df[cols_to_mean].mean()).transpose()
final_df = sum_data.join(mean_data)
final_df['team'] = team
final_df['matches'] = len(df)
frames.append(final_df)
full_stat = pd.concat(frames)
full_stat = full_stat[['team', 'matches', 'wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'xG', 'npxG', 'xGA', 'npxGA', 'npxGD', 'ppda_coef', 'oppda_coef', 'deep', 'deep_allowed', 'xpts']]
full_stat.sort_values('pts', ascending=False, inplace=True)
full_stat.reset_index(inplace=True, drop=True)
full_stat['position'] = range(1,len(full_stat)+1)
full_stat['xG_diff'] = full_stat['xG'] - full_stat['scored']
full_stat['xGA_diff'] = full_stat['xGA'] - full_stat['missed']
full_stat['xpts_diff'] = full_stat['xpts'] - full_stat['pts']
cols_to_int = ['wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'deep', 'deep_allowed']
full_stat[cols_to_int] = full_stat[cols_to_int].astype(int)
col_order = [‘league’,’year’,'position', 'team', 'matches', 'wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'xG', 'xG_diff', 'npxG', 'xGA', 'xGA_diff', 'npxGA', 'npxGD', 'ppda_coef', 'oppda_coef', 'deep', 'deep_allowed', 'xpts', 'xpts_diff']
full_stat = full_stat[col_order]
full_stat = full_stat.set_index('position')
# print(full_stat.head(20))
season_data[season] = full_stat
df_season = pd.concat(season_data)
full_data[league] = df_seasonTo analyse our data with Django, we need to export the data to a CSV file. To do this, copy and paste the code below.
data = pd.concat(full_data)
data.to_csv('understat.com.csv')You must first establish an account before you can build a Fauna database. You may create another after you've created one by clicking the CREATE DATABASE button on the dashboard.

Create one collection in your database, the
SOCCER_DATA collection. The SOCCER_DATA collection will store the data we extract to our CSV file in the database. For the History days and TTL, use the default values provided and save.
Create two indexes for your collections;
check_name and get_all_teams_data. The get_all_teams_data index will allow you to scroll through data in the SOCCER_DATA collection. It has one term, which is the matches field. This term will enable you to match data with the matches for easy querying.The
check_name will allow you to scroll through data in the SOCCER_DATA collection. This index will enable matching with the team field to perform queries.
To generate an API key, go to the security tab on the left side of your dashboard, then click
New Key to create a key. You will then be required to provide a database to connect to the key. After providing the information required, click the SAVE button.
After saving your key, Fauna will present you with your secret key in the image above (hidden here for privacy). Make sure to copy your secret key from the dashboard and save it somewhere you can easily retrieve it for later use.

The Django application will collect data from the CSV file, store it in the Fauna database and display it on the homepage user interface. To create a Django project, run the commands below:
django-admin startproject FAUNA_WEBSCRAPER
Django-admin startapp APPAfter creating the Django project, we need to create another application before diving into the main code logic. Follow the steps below to set up your Django application.
APP to installed apps in the settings.py file as seen in the code below:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'APP',
]urls.py file with python code below:
from django.contrib import admin
from django.urls import path, include
from django.conf import settings
from django.contrib.staticfiles.urls import staticfiles_urlpatterns
from django.contrib.staticfiles.urls import static
urlpatterns = [
path('admin/', admin.site.urls),
path('', include("APP.urls")),
]
urlpatterns += staticfiles_urlpatterns()
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)urls.py file in the APP folder, then paste the python code below.
from django.conf import settings
from django.conf.urls.static import static
from django.urls import path, include
from . import views
app_name = "App"
urlpatterns = [
path("", views.index, name="index"),
]APP directory to handle the application user interface(i.e. templates and static folder).templates folder, an HTML file and a CSS file. The HTML should be index.html, and the CSS file should be style.css. Copy and paste the code below in their respective files.
{% load static %}
<!DOCTYPE html>
<html>
<head>
<link href="{% static 'style.css' %}" rel="stylesheet">
<h1>Fauna Sport Aggregator</h1>
</head>
<body>
<table class="content-table">
<thead>
<tr>
<th>Position</th>
<th>Team</th>
<th>Matches</th>
<th>Wins</th>
<th>Draws</th>
<th>Loses</th>
<th>Points</th>
</tr>
</thead>
<tbody>
{% for team in team_list_data %}
<tr>
<td>{{team.position}}</td>
<td>{{team.team}}</td>
<td>{{team.matches}}</td>
<td>{{team.wins}}</td>
<td>{{team.draws}}</td>
<td>{{team.loses}}</td>
<td>{{team.points}}</td>
</tr>
{% endfor %}
</tbody>
</table>
</body>
</html>#style.css
h1 {
color: #0000A0;
font-family: sans-serif;
}
.content-table {
border-collapse: collapse;
margin: 25px 0;
font-size: 1.0em;
font-weight: bold;
font-family: sans-serif;
min-width: 400px;
border-radius: 5px 5px 0 0;
overflow-hidden: hidden;
box-shadow: 0 0 20px rgba(0, 0, 0, 0.15);
}
.content-table thead tr {
background-color: #0000A0;
color: #FFFFFF;
text-align: left;
font-weight: bold;
}
.content-table th,
.content-table td {
padding: 15px 25px;
}
.content-table tbody tr {
border-bottom: 1px solid #dddddd;
}
.content-table tbody tr:nth-of-type(even) {
background-color: #f3f3f3;
color: #0000A0;
font-weight: bold
}
.content-table tbody tr:last-of-type {
border-bottom: 2px solid #0000A0;
}
.content-table tbody tr:hover {
background-color: #D3D3D3;
}APP folder.views.py file.
from django.shortcuts import render
import csv
from faunadb import query as q
from faunadb.objects import Ref
from faunadb.client import FaunaClient
# Create your views here.
client = FaunaClient(secret="fauna_secret_key", domain="db.eu.fauna.com",
# NOTE: Use the correct domain for your database's Region Group.
port=443,
scheme="https")
def index(request):
team_data_list = []
headers_list = []
paginate_data=client.query(q.paginate(q.match(q.index("get_all_teams_data"), "38")))
all_data = [
q.get(
q.ref(q.collection("SOCCER_DATA"), paginate.id())
) for paginate in paginate_data["data"]
]
team_list_data = [i["data"] for i in client.query(all_data)]
context={"team_list_data":client.query(team_list_data)}
index = 0
with open("understat.com.csv", 'r') as data:
for line in csv.reader(data):
index += 1
if index > 1:
team_dict = {}
for i, elem in enumerate(headers_list):
team_dict[elem] = line[i]
team_data_list.append(team_dict)
else:
headers_list = list(line)
for record in team_data_list[:20]:
try:
team_data_check = client.query(q.get(q.match(q.index('check_name'),record["team"])))
except:
team_record = client.query(q.create(q.collection("SOCCER_DATA"), {
"data": {
"matches":record["matches"],
"position":record["position"],
"team":record["team"],
"wins": record["wins"],
"draws": record["draws"],
"loses":record["loses"],
"points":record["pts"]
}
}))
return render(request,"index.html",context)python manage.py migrate
python manage.py runserverAfter following the steps listed above, your
SOCCER_DATA collection should be like the one in the image below.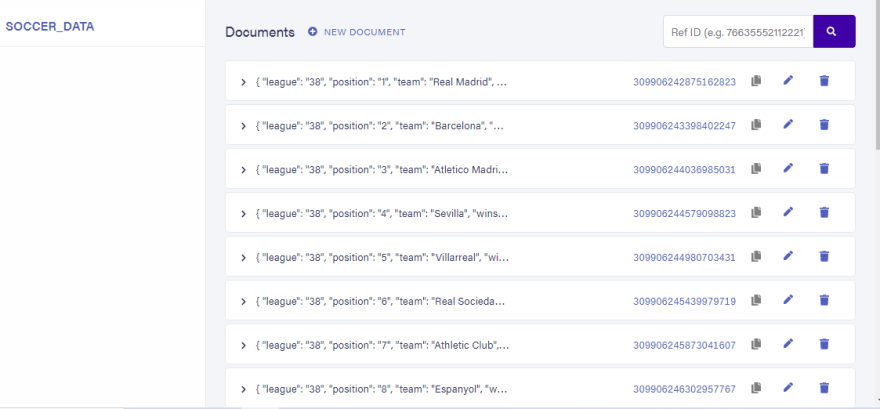
Go to http://127:0.0.1.8000 to see your Django application. Your homepage should be similar to the one in the image below.
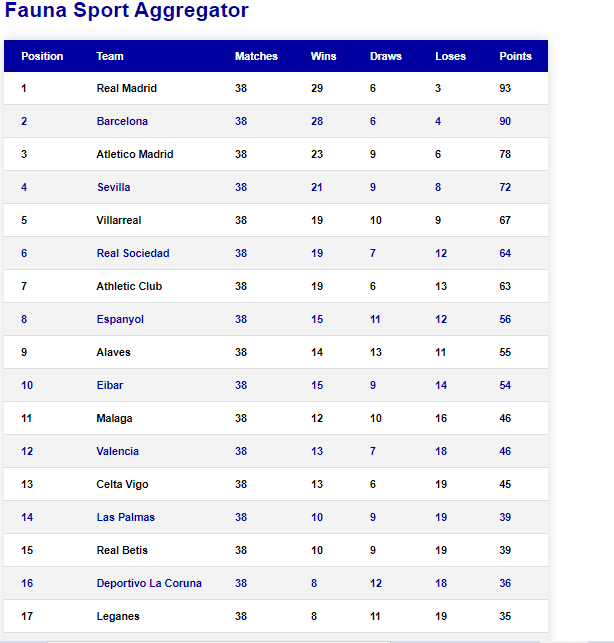
This file is where we built the logic for the backend. We started by importing the required modules as seen in the python code below:
from django.shortcuts import render
import csv
from faunadb import query as q
from faunadb.objects import Ref
from faunadb.client import FaunaClientNext, we initialised the Fauna client using the secret key we generated earlier.
client = FaunaClient(secret="fnAETH3xELAAxp99WYA-8_xMLqFM1uMTfAwZYmZO", domain="db.eu.fauna.com",
# NOTE: Use the correct domain for your database's Region Group.
port=443,
scheme="https")We then needed to extract the data from our excel sheet before saving it into our
SOCCER_DATA collection. We did this by reading and saving the data in the CSV file to a list variable team_data_list in our program.team_data_list = []
headers_list = []
index = 0
with open("understat.com.csv", 'r') as data:
for line in csv.reader(data):
index += 1
if index > 1:
team_dict = {}
for i, elem in enumerate(headers_list):
team_dict[elem] = line[i]
team_data_list.append(team_dict)
else:
headers_list = list(line)Next, we needed to extract data from our list
team_data_list variable, then stored them in the SOCCER_DATA collection. To do this, we iterated every data in the list and created a request with the Fauna client to save the data passed in the dictionary we defined to the collection. We only saved the first 20 data from the list for this tutorial, so we don’t exceed our free account rate limit.for record in team_data_list[:20]:
try:
team_data_check = client.query(q.get(q.match(q.index('check_name'),record["team"])))
except:
team_record = client.query(q.create(q.collection("SOCCER_DATA"), {
"data": {
"matches":record["matches"],
"position":record["position"],
"team":record["team"],
"wins": record["wins"],
"draws": record["draws"],
"loses":record["loses"],
"points":record["pts"]
}
}))Next, we queried the data in the collection using the
get_all_team_data1 Fauna index to match data for all teams with 38 matches. We paginated the queried data using Fauna’s paginate method, then created a list variable called team_list_data from it. Finally, we passed the list’s data to the front end user interface for display on a table. In this article, we built a python web scraper to extract soccer data from a website. We also learned how to utilise this data in a Django application with Fauna's serverless database. We saw how easy it is to integrate Fauna into a Python application and got the chance to explore some of its core features and functionalities.
If you have any questions, don't hesitate to contact me on Twitter: @LordChuks3.
Written in connection with the Write with Fauna Program.
46