15
loading...

pip install install requests beautifulsoup4 playwright "celery[redis]"
npx playwright installtasks.py and run it. If you run it as a regular python file, only one string will be printed. The console will print two different lines if you run it with celery -A tasks worker.demo function call. Direct call implies "execute that task," while delay means "enqueue it for a worker to process." Check the docs for more info on calling tasks.celery command will not end; we need to kill it by exiting the console (i.e., ctrl + C). We'll need it several times because Celery does not reload after code changes.extract_links will get all the links on the page except the nofollow ones. We will add filtering options later.main.py with the following content. We will create a list named crawling:to_visit and push the starting URL. Then we will go into a loop that will query that list for items and block for a minute until an item is ready. When an item is retrieved, we call the crawl function, enqueuing its execution.links and pushing them all, but it is not a good idea without deduplication and a maximum number of pages. We will keep track of all the queued and visited using sets and exit once their sum exceeds the maximum allowed.redis-cli or a GUI like redis-commander. There are commands for deleting keys (i.e., DEL crawling:to_visit) or flushing the database (careful with this one).tasks.py and main.py. We will create another two to host crawler-related functions (crawler.py) and database access (repo.py). Please look at the snippet below for the repo file, it is not complete, but you get the idea. There is a GitHub repository with the final content in case you want to check it.crawler file will have the functions for crawling, extracting links, and so on.parsers/defaults.py).parserlist.py. To simplify a bit, we allow one custom parser per domain. The demo includes two domains for testing: scrapeme.live and quotes.toscrape.com.scrapeme first as an example. Check the repo for the final version and the other custom parser.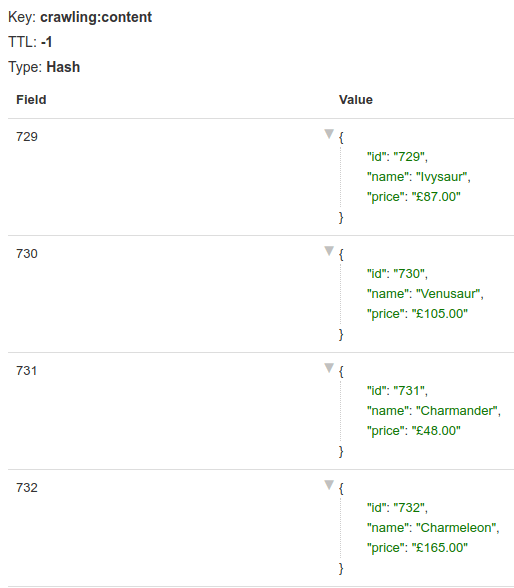
quotes site, we need to handle it differently since there is no ID per quote. We will extract the author and quote for each entry in the list. Then, in the store_content function, we'll create a list for each author and add that quote. Redis handles the creation of the lists when necessary.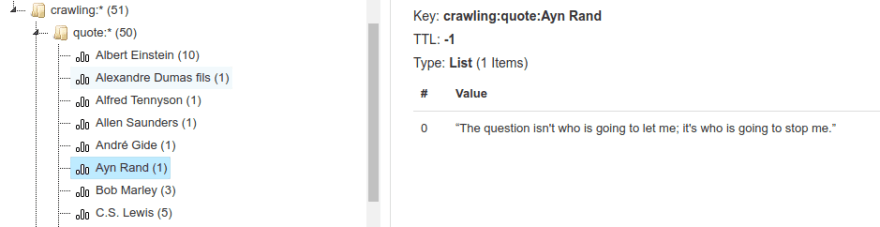
parserlist.py referencing it. We could go a step further and "auto-discover" them, but no need to complicate it even more.requests.get, which can be inadequate in some cases. Say we want to use a different library or headless browser, but just for some cases or domains. Loading a browser is memory-consuming and slow, so we should avoid it when it is not mandatory. The solution? Even more customization. New concept: collector.collectors/basic.py and paste the already known get_html function. Then change the defaults to use it by importing it. Next, create a new file, collectors/headless_firefox.py, for the new and shiny method of getting the target HTML. As in the previous post, we will be using playwright. And we will also parametrize headers and proxies in case we want to use them. Spoiler: we will.get_html for that parser (i.e., parsers/scrapemelive.py).fake.py collector used in scrapemelive.py. Since we used that website for intense testing, we downloaded all the product pages the first time and stored them in a data folder. We can customize with a headless browser, but we can do the same with a file reader, hence the "fake" name.headers.py. We won't paste the entire content here, there are three different sets of headers for a Linux machine, and it gets pretty long. Check the repo for the details.random_headers to get one of the available options. We will see a usage example in a moment.proxies.py. It will contain a list of them grouped by the provider. In our example, we will include only free proxies. Add your paid ones in the proxies dictionary and change the default type to the one you prefer. If we were to complicate things, we could add a retry with a different provider in case of failure.tasks.py for Celery and main.py to start queueing URLs. From there, we begin storing URLs in Redis to keep track and start crawling the first URL. A custom or the default parser will get the HTML, extract and filter links, and generate and store the appropriate content. We add those links to a list and start the process again. Thanks to Celery, once there is more than one link in the queue, the parallel/distributed process starts.
celery -A tasks worker --concurrency=20 -n worker1 and ... -n worker2. The way to go is to do the same in other machines as long as they can connect to the broker (Redis in our case). We could even add or remove workers and servers on the fly, no need to restart the rest. Celery handles the workers and distributes the load.-n worker2.@app.task(rate_limit="30/m"). But remember that it would affect the task, not the crawled domain.allow_url_filter part, we should also add a robots.txt checker. For that, the robotparser library can take a URL and tell us if it is allowed to crawl it. We can add it to the default or as a standalone function, and then each scraper decides whether to use it. We thought it was complex enough and did not implement this functionality.mtime() and reread it from time to time. And also, cache it to avoid requesting it for every single URL.15