
32
How to measure speech recognition latency
One of the obvious applications of speech recognition is voice assistants. While there's an abundance of smart devices on the market, Amazon Echo family being probably the most famous of them, there is still plenty of cases where you might want to build your own solution. You would have to choose from a wide variety of commercial and open source offerings for speech recognition and NLP at the very least. In this article, I'll show how to measure speech recognition latency, i.e. determine how quickly it can return transcription required for your application to understand user's request.
Typically voice assistants perform streaming speech recognition, meaning they send a continuous stream of digital audio to whatever speech-to-text backend you're using. That allows to minimize the time required to transcribe the speech, understand user's intent and finally perform the requested operation. Obviously, if you're evaluating different vendors or open source solutions for speech recognition, you'll likely want to measure their latency, because your users' experience will largely depend on how low it is.
But how do measure latency if there's a continuous stream of audio and no unambiguous response time like in the case of a REST API?
Audio stream originates at some point in time 0 (zero) and sound is then being sent for processing in equal chunks, in this example 100ms each. If your recording sample rate is 16 kHz, 100ms of sound will be represented by 1600 samples. Assuming you want your voice assistant to turn on a smart bulb, command's representation in 100ms chunks of audio would look something like this (timings on the X axis are arbitrary):
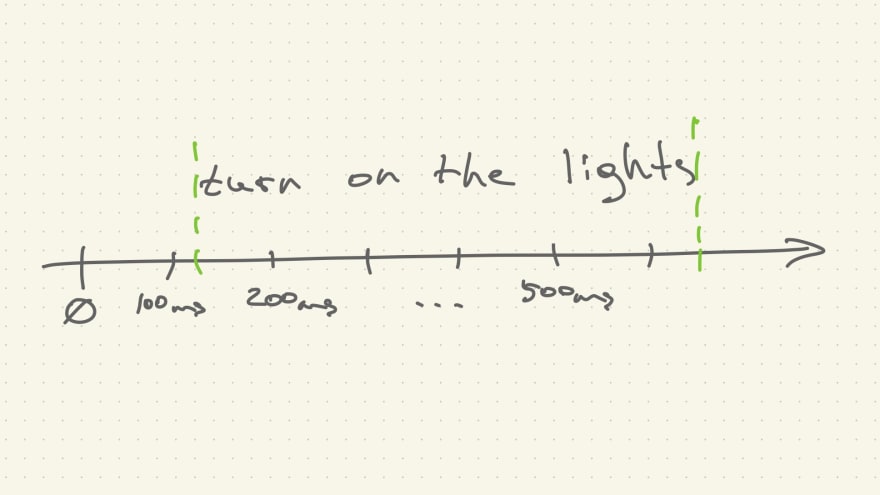
Speech recognition will probably yield some interim results up until the point when the transcript matches some sort of definition of a command, be it a NLP pipeline or a simple regular expression. Aligned on the same time axis as the audio stream, results will look like on the image below. Difference between the end of command pronunciation and the moment matching transcript arrives is our latency.
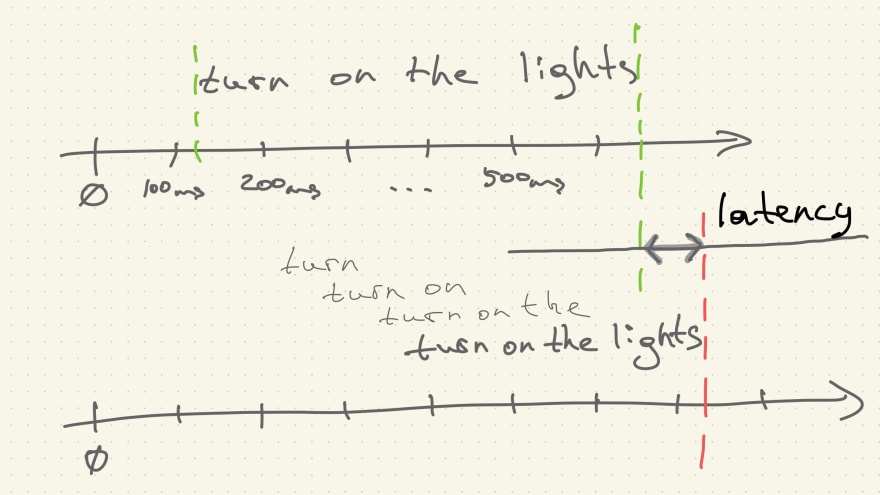
Speech recognition will probably yield some interim results up until the point when the transcript matches some sort of definition of a command, be it a NLP pipeline or a simple regular expression. Aligned on the same time axis as the audio stream, results will look like on the image below. Difference between the end of command pronunciation and the moment matching transcript arrives is our latency.
Let's put the algorithm to test and implement it in Python using Google Cloud Speech-to-text streaming API. The API client implementation itself is a slightly modified Google Cloud tutorial on streaming recognition, so I'll focus mainly on the sound handling logic and latency calculation.
We will attempt to transcribe an audio file so that the experiment would be repeatable but we'll emulate a realtime streaming. First, let's define a function that accepts the target file name and the pattern we expect transcript to match:
def match_command(
self, filename: str, pattern: str, language_code: str
) -> Tuple[str, int]:
info = sf.info(filename)
client = StreamingClient(info.samplerate, language_code)
for transcript in client.recognize(
self.generate_request_stream(filename, info.samplerate)
):
match = re.match(pattern, transcript)
if match:
self.closed = True
return transcript, current_time_ms() - self.command_end_ts
return None, NoneHere we initialize the API client with sample rate and language code, feed audio request generator to it and then iterate recognition results. Next, let's look at the request generator itself.
For starters, no user starts speaking the millisecond her microphone is turned on. So to be as close to real life as possible, we'll stream a little bit of silence at the beginning. It will be a random amount of time between 100ms (chunk size) and 2 seconds.
pre_silence = np.random.choice(
[*range(chunk_size, samples_per_ms * 2000 + 1, chunk_size)], 1
)[0]
pre_silence_sent = 0
while pre_silence_sent <= pre_silence:
yield np.zeros(chunk_size, dtype="int16").tobytes()
pre_silence_sent += chunk_size
time.sleep(0.1)The next step is to stream the audio file itself, still emulating real time by calling
time.sleep every time. I'm using an excellent library Soundfile to open the file, strip WAVE headers and read samples. I'm also capturing a timestamp of when a successive chunk is about to be sent - we will need the last timestamp to calculate latency in the end.with sf.SoundFile(filename, mode="r") as wav:
while wav.tell() < wav.frames:
sound_for_recognition = wav.read(chunk_size, dtype="int16")
self.command_end_ts = current_time_ms()
yield sound_for_recognition.tobytes()
time.sleep(0.1)That would actually be a little bit inaccurate way to capture a moment when command pronunciation ended. The last chunk will most likely be shorter than 100ms worth of samples because no one alighs their speech to time scale 🙂 That means that actual speech has ended at least
100 - last_chunk_duration milliseconds ago. Let's account for that:with sf.SoundFile(filename, mode="r") as wav:
while wav.tell() < wav.frames:
sound_for_recognition = wav.read(chunk_size, dtype="int16")
if sound_for_recognition.shape[0] < chunk_size:
last_chunk_size = sound_for_recognition.shape[0]
sound_for_recognition = np.concatenate(
(
sound_for_recognition,
np.zeros(
chunk_size - sound_for_recognition.shape[0],
dtype="int16",
),
)
)
self.command_end_ts = (
current_time_ms()
- (chunk_size - last_chunk_size) / samples_per_ms
)
else:
self.command_end_ts = current_time_ms()
yield sound_for_recognition.tobytes()
time.sleep(0.1)Now that we streamed all of our voice command recording, we could just end the request, however, that would force the speech-to-text backend to flush transcription hypotheses, which will result in artificially lower latency. To mitigate that, we'll stream chunks of silence until the moment when the matching transcript will naturally arrive. Speech-to-text backend will likely use voice activity detection (VAD) to determine that speech has ended and it's time to flush recognition results.
while not self.closed:
yield np.zeros(chunk_size, dtype="int16").tobytes()
time.sleep(0.1)And that's it! Going back to
match_command function, it contains a listening loop for results - as soon as matching transcript arrives, we capture that timestamp, subtract the timestamp of when command pronunciation ended, and that will be our latency.Depending on your location and internet connection you may get different results, but I get latency of about 700ms for my reference files, which means that unless there's really complex and time-consuming post-processing, the hypothetical voice assistant would be able to provide response in under a second, which most users would consider to be pretty fast.
The complete code for this article is on Github. For now I've provided implementation only for Google Cloud Speech-to-text but will try to add more vendors for comparison over time.
Cover photo by Thomas Kolnowski on Unsplash
32