
47
No Cost Data Scraping With GitHub Actions And Neo4j Aura
When working with data a common task is fetching data from some external source on a recurring basis and importing into a database for further analysis or as part of our application. Setting up servers to handle this can be time consuming and error prone. I recently came across a workflow using GitHub Actions and Neo4j Aura that makes this a breeze and with the free tiers of both GitHub Actions and Neo4j Aura is free to set up and run forever - great for side projects!
In this post we'll take a look at setting up this workflow to scrape data from the Lobsters news aggregator and import into a Neo4j Aura Free instance using GitHub Actions. We built this on the Neo4j livestream so check out the recording if you prefer video:

I've been thinking about social networks recently and want to build an application to help explore relevant news articles using graph visualization so building something using data from Lobsters seems like a great fit. We want to import data about users and article submissions into Neo4j as the basis of our application, but how to get started? Fortunately, Lobsters makes two JSON endpoints available to fetch data about the newest and the "hottest" submissions. Each has a similar format and looks like this.

Now that we know what our JSON data looks like we can think about how to start importing this data into Neo4j Aura as a graph.
Let's sign-in to Neo4j Aura and create an Aura Free instance:
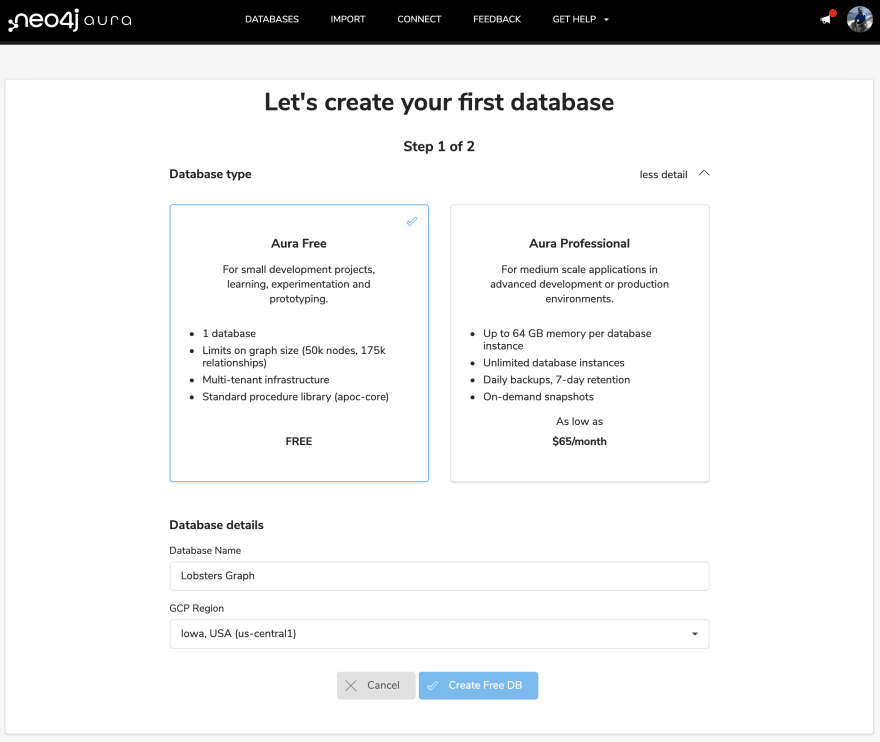
We'll immediately be given a generated password that we'll need to save to access our Neo4j Aura instance. We can change this later.
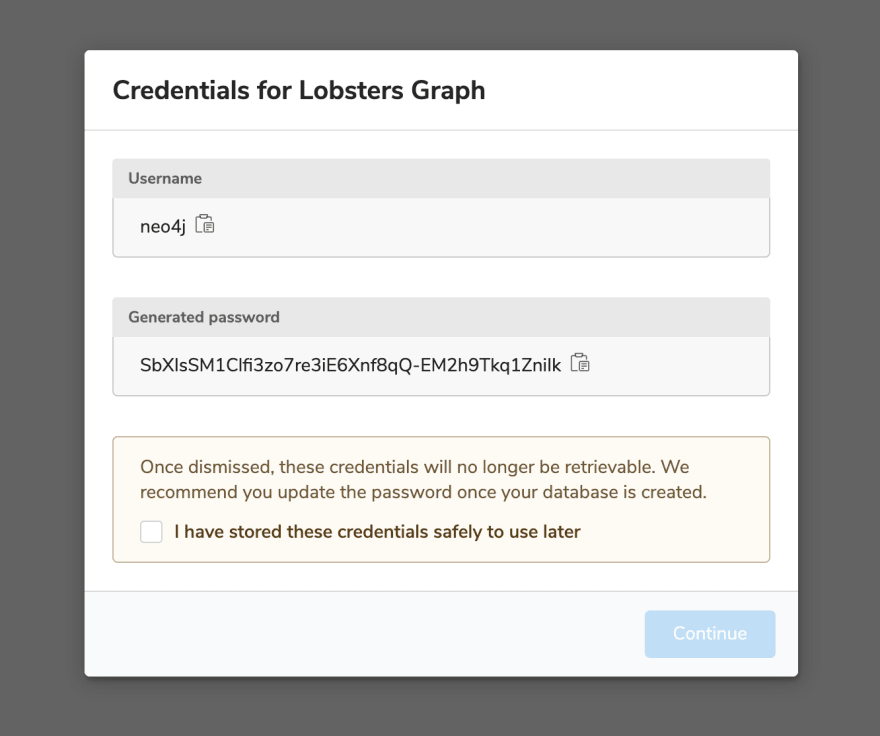
Next, our Aura instance will take a few moments to be provisioned.
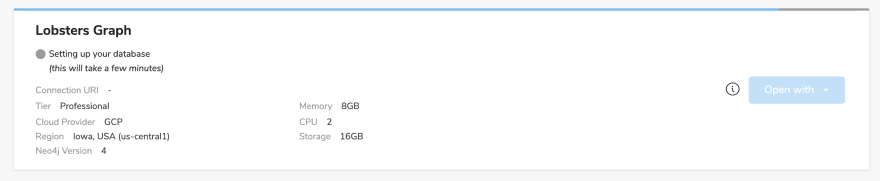
Once our Neo4j Aura instance is ready we'll see the connection string in the dashboard. Let's open up Neo4j Browser to start working with our data.

Since we're working with JSON data we can make use of the
apoc.load.json procedure from the APOC standard library to import a JSON file using Cypher. First, let's just pull this file in to make sure we can parse it. This Cypher statement will parse the newest Lobsters submissions and return an array of objects that we can work with in Cypher:CALL apoc.load.json("https://lobste.rs/newest.json") YIELD value
RETURN valueIf we run this in Neo4j Browser we'll see the parsed array of objects returned. We haven't actually created any data in the database yet - we're just parsing the JSON file and returning the results.

We'll use Cypher to define the graph structure we want to create from this data, but we first need to think a bit about how we want to model this data as a graph. I think of graph modeling as a multi-step process, at the highest level the steps are:

Now we can write the Cypher to import our data according to this model. We'll use
apoc.load.json to parse the JSON file, then use UNWIND to iterate over this array of objects. We'll then use the MERGE Cypher clause to add users, articles, and tags to the database. The MERGE statement allows us to avoid creating duplicates in the graph - with MERGE only patterns that don't already exist in the graph are created.This makes our import statement idempotent - we can run it over and over again on the same data and we won't make any changes to the database unless the data changes.
CALL apoc.load.json("https://lobste.rs/newest.json") YIELD value
UNWIND value AS article
MERGE (s:User {username: article.submitter_user.username})
ON CREATE SET s.about = article.submitter_user.about,
s.created = DateTime(article.submitter_user.created_at),
s.karma = article.submitter_user.karma,
s.avatar_url = "https://lobsete.rs" + article.submitter_user.avatar_url
MERGE (i:User {username: article.submitter_user.invited_by_user})
MERGE (i)<-[:INVITED_BY]-(s)
MERGE (a:Article {short_id: article.short_id})
SET a.url = article.url,
a.score = article.score,
a.created = DateTime(article.created_at),
a.title = article.title,
a.comments = article.comments_url
MERGE (s)-[:SUBMITTED]->(a)
WITH article, a
UNWIND article.tags AS tag
MERGE (t:Tag {name: tag})
MERGE (a)-[:HAS_TAG]->(t)To verify we've imported this data correctly we can visualize it in Neo4j Browser - let's check to make sure the property values are what we expect and makes sense.

That's great, but the Lobsters data will be continually changing as new articles are submitted and voted on - we want to import it on an ongoing basis. Let's use GitHub Actions to do this!
The GitHub team recently released the Flat Data project which aims to simplify data and ETL workflows. Flat Data includes the Flat Data GitHub Action, a VSCode extension for creating Flat Data workflows, and a web app for viewing data. The Flat Data Action allows us to schedule a GitHub action to periodically fetch data via a URL or SQL statement, check the data into git, and run a postprocessing step to, for example, insert data into a database.
This sounds perfect for what we want to accomplish with Lobsters and Neo4j Aura - let's give it a try! First, we'll sign into GitHub and create a new repository:

Because we selected "Add a README file" we can immediately start to make commits to our repo and use the built-in editor in the GitHub web UI to set up our Flat Data Action. We can also clone the repo locally, but I'll just use the built-in text editor.

To create a new GitHub action we'll add a new file
.github/workflows/lobsters.yml. In this YAML file we willactions/checkout@v2 actiongithubocto/flat@v2 Action to fetch our Lobsters JSON file and check it into our repo as newest.json
name: Lobsters Data Import
on:
push:
paths:
- .github/workflows/lobsters.yml
workflow_dispatch:
schedule:
- cron: '*/60 * * * *'
jobs:
scheduled:
runs-on: ubuntu-latest
steps:
- name: Check out repo
uses: actions/checkout@v2
- name: Fetch newest
uses: githubocto/flat@v2
with:
http_url: https://lobste.rs/newest.json
downloaded_filename: newest.jsonUsing the in-browser editor in GitHub we should see something like this:
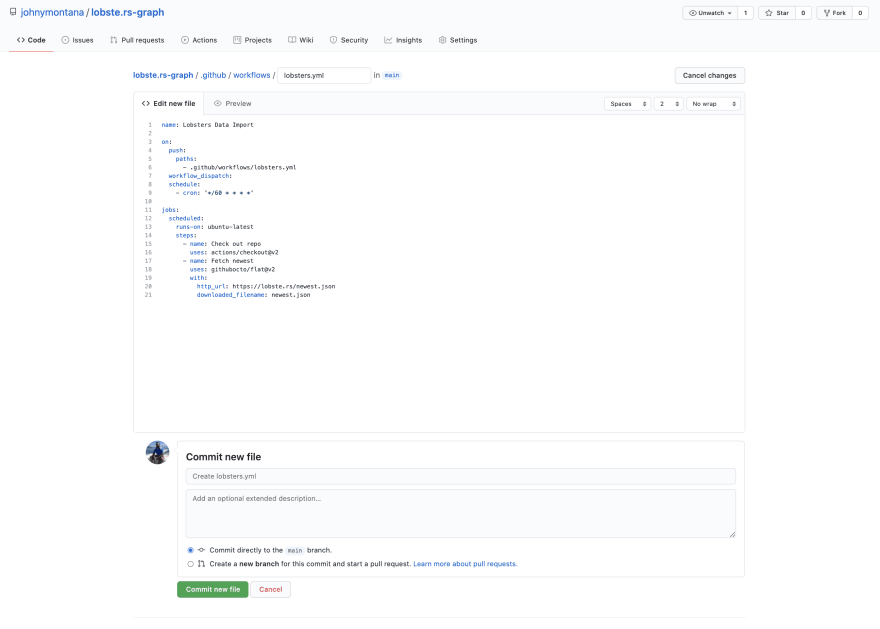
Our GitHub Action will run immediately after committing the new file and in a few seconds we'll see a new commit, checking in the
newest.json file with the data from Lobsters.
Great - we've fetched the newest Lobsters article submissions and checked them into our repository and scheduled a GitHub Action to refresh this data every hour. Now we're ready to update our GitHub Action to import data into Neo4j.
First, we'll need to add secrets to our GitHub repository so our Action can connect to our Neo4j Aura instance and we don't have to expose our connection credentials. In GitHub select the "Settings" tab then navigate to the "Secrets" section and select the "New repository secret" button.
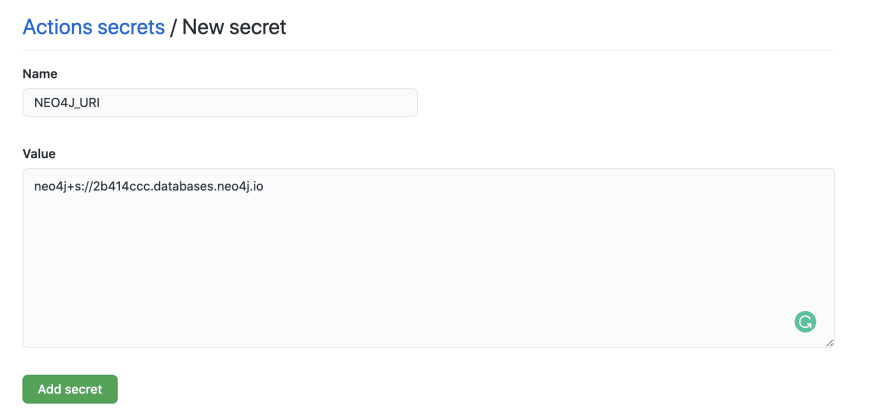
We'll create three secrets
NEO4J_USER, NEO4J_PASSWORD, and NEO4J_URI with the connection credentials specific to the Neo4j Aura instance we created earlier.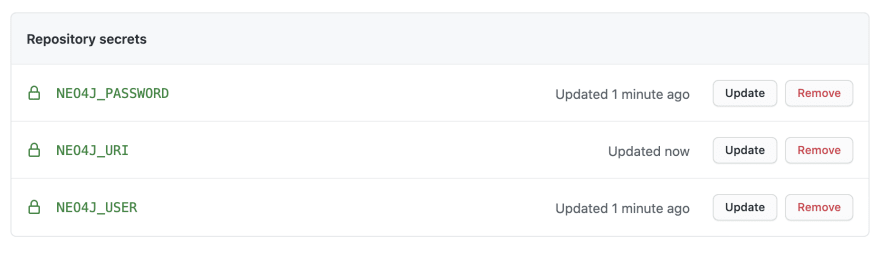
We'll now be able to reference these secrets values in the YAML file where we define our GitHub Action to connect to our Neo4j Aura instance.
The Flat Data GitHub Action includes support for a post-processing step that allows us to run a JavaScript or Python script after the data is fetched. We could write a simple script to use the Neo4j language driver to connect to our Neo4j Aura instance and run a Cypher import statement, passing in the JSON data as a Cypher parameter, however there is also the Flat Graph GitHub Action which does just this.
Flat Graph is designed to work with the Flat Data GitHub Action and allows us to declare the Cypher import statement we want to run and our Neo4j Aura connection credentials as another step in our GitHub Action. Flat Graph will load the specified JSON file and pass it as a Cypher parameter called
$value so our Cypher import statement just needs to reference this Cypher parameter to work with the data fetched by Flat Data in the previous step of our Action.We'll use the Cypher statement we wrote above using
apoc.load.json, but adapt it to use this convention. We'll also reference the Neo4j Aura connection credentials we defined as GitHub secrets. Let's update our lobsters.yml file:name: Lobsters Data Import
on:
push:
paths:
- .github/workflows/lobsters.yml
workflow_dispatch:
schedule:
- cron: '*/60 * * * *'
jobs:
scheduled:
runs-on: ubuntu-latest
steps:
- name: Check out repo
uses: actions/checkout@v2
- name: Fetch newest
uses: githubocto/flat@v2
with:
http_url: https://lobste.rs/newest.json
downloaded_filename: newest.json
- name: Neo4j import
uses: johnymontana/flat-[email protected]
with:
neo4j-user: ${{secrets.NEO4J_USER}}
neo4j-password: ${{secrets.NEO4J_PASSWORD}}
neo4j-uri: ${{secrets.NEO4J_URI}}
filename: newest.json
cypher-query: >
UNWIND $value AS article
MERGE (s:User {username: article.submitter_user.username})
ON CREATE SET s.about = article.submitter_user.about,
s.created = DateTime(article.submitter_user.created_at),
s.karma = article.submitter_user.karma,
s.avatar_url = "https://lobsete.rs" + article.submitter_user.avatar_url
MERGE (i:User {username: article.submitter_user.invited_by_user})
MERGE (i)<-[:INVITED_BY]-(s)
MERGE (a:Article {short_id: article.short_id})
SET a.url = article.url,
a.score = article.score,
a.created = DateTime(article.created_at),
a.title = article.title,
a.comments = article.comments_url
MERGE (s)-[:SUBMITTED]->(a)
WITH article, a
UNWIND article.tags AS tag
MERGE (t:Tag {name: tag})
MERGE (a)-[:HAS_TAG]->(t)Once we commit the change our Action will run - loading the latest Lobsters article data into our Neo4j Aura instance. This Action will run each hour updating our database with the latest Lobsters data.
We've now set up a serverless data scraping workflow to fetch all new articles submitted to Lobsters and import into Neo4j Aura using GitHub Actions. Next, we'll take a look at data visualization options and we begin to explore this dataset and build a web application to help us find relevant information. If you'd like to follow along we'll be coding this on the Neo4j Livestream on Twitch and YouTube. You can also subscribe to my newsletter to be notified as new posts are up. Happy graphing!
 johnymontana
/
lobste.rs-graph
johnymontana
/
lobste.rs-graph
Importing Lobste.rs data into Neo4j Aura using GitHub Actions

47